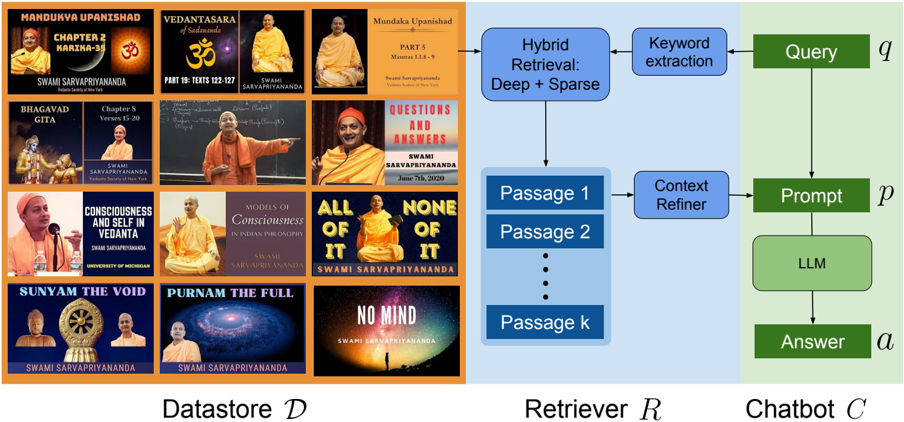
## Diagram: Knowledge Retrieval and Chatbot System Architecture
### Overview
The diagram illustrates a three-stage system for processing queries using a knowledge base of Swami Sarvapriyananda's teachings. The flow progresses from a Datastore (D) containing multimedia content, through a Retriever (R) that processes passages, to a Chatbot (C) that generates answers using an LLM (Large Language Model).
### Components/Axes
1. **Datastore (D)**:
- Contains 12 multimedia entries featuring Swami Sarvapriyananda
- Titles include:
- "HANDUVYA UPANISHAD CHAPTER 2 KARMA-33"
- "VEDANTASARA OF SANATANDA"
- "SUNYAM THE VOID"
- "PURNAM THE FULL"
- "NO MIND"
- Visual elements: Orange/yellow color scheme, monk imagery, Sanskrit text
2. **Retriever (R)**:
- Hybrid Retrieval: Deep + Sparse
- Keyword Extraction
- Context Refiner
- Processes passages (Passage 1 to Passage k)
3. **Chatbot (C)**:
- Query (q) → Keyword Extraction → Prompt (p)
- LLM (Large Language Model)
- Answer (a)
### Flow Direction
- Left-to-right progression: Datastore → Retriever → Chatbot
- Arrows indicate data flow between components
- Vertical alignment of passages in Retriever suggests sequential processing
### Key Observations
1. The system integrates multimedia content with text-based retrieval
2. Hybrid retrieval combines deep learning and sparse methods
3. Context refinement precedes LLM processing
4. All passages originate from Swami Sarvapriyananda's teachings
5. No numerical data or quantitative metrics are shown
### Interpretation
This architecture demonstrates a RAG (Retrieval-Augmented Generation) system specialized for Swami Sarvapriyananda's teachings. The hybrid retrieval approach suggests optimization for both semantic understanding (deep) and keyword matching (sparse). The context refiner likely improves passage relevance before LLM processing, while the multimedia datastore provides rich source material. The absence of quantitative metrics implies this is a conceptual diagram rather than a performance benchmark.
The system's design prioritizes:
1. Content specificity (Swami's teachings)
2. Multimodal input (text + images)
3. Semantic understanding (hybrid retrieval)
4. Context-aware generation (LLM with refined prompts)