## Diagram: LLM-Based Question Answering System
### Overview
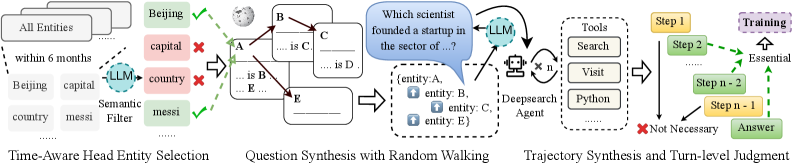
The image illustrates a system for generating and answering questions using a Large Language Model (LLM). The process is divided into four main stages: Time-Aware Head Entity Selection, Question Synthesis with Random Walking, Trajectory Synthesis and Turn-level Judgment.
### Components/Axes
* **Time-Aware Head Entity Selection:** This stage involves selecting relevant entities from a larger set of "All Entities" within a specified time frame ("within 6 months"). A semantic filter, potentially using an LLM, is applied to refine the selection. Examples of entities are "Beijing", "capital", "country", and "messi". Some entities are marked with a green checkmark, indicating they are selected, while others are marked with a red "X", indicating they are rejected.
* **Question Synthesis with Random Walking:** This stage generates question templates based on the selected entities. The diagram shows a template with blanks to be filled in (e.g., "... is C"). The entities A, B, C, and E are used to populate these templates. The output is a question like "Which scientist founded a startup in the sector of...?", along with a set of entities (A, B, C, E) associated with the question.
* **Trajectory Synthesis:** This stage involves using a "Deepsearch Agent" to find answers to the generated questions. The agent utilizes tools like "Search", "Visit", and "Python". The agent interacts with the LLM multiple times (indicated by "x n").
* **Turn-level Judgment:** This stage evaluates the steps taken to answer the question. Steps are marked as either "Essential" (leading to the "Answer") or "Not Necessary". The steps are labeled as "Step 1", "Step 2", ..., "Step n-2", "Step n-1". The "Training" block is connected to the "Essential" path.
### Detailed Analysis
* **Time-Aware Head Entity Selection:**
* "All Entities" is the initial set of entities.
* "within 6 months" indicates a time constraint for entity selection.
* "Beijing" and "messi" are marked with green checkmarks, indicating successful selection.
* "capital" and "country" are marked with red "X" marks, indicating rejection.
* "Semantic Filter" uses an "LLM" to filter entities.
* **Question Synthesis with Random Walking:**
* Question templates are generated with blanks to be filled.
* Entities A, B, C, D, and E are used in the templates.
* The output is a question and a set of associated entities.
* **Trajectory Synthesis:**
* "Deepsearch Agent" uses tools to find answers.
* Tools include "Search", "Visit", and "Python".
* The agent interacts with the "LLM" multiple times.
* **Turn-level Judgment:**
* Steps are evaluated as "Essential" or "Not Necessary".
* "Training" is connected to the "Essential" path.
* The process leads to the "Answer".
### Key Observations
* The system uses an LLM at multiple stages: semantic filtering and trajectory synthesis.
* The process involves generating questions, finding answers, and evaluating the steps taken.
* The system incorporates time awareness in entity selection.
### Interpretation
The diagram illustrates a complex question-answering system that leverages LLMs for various tasks, including entity selection, question generation, and answer retrieval. The system's modular design allows for the integration of different tools and techniques. The inclusion of a turn-level judgment component suggests a focus on improving the efficiency and effectiveness of the question-answering process through training and feedback. The time-aware entity selection indicates that the system is designed to handle questions that require up-to-date information.