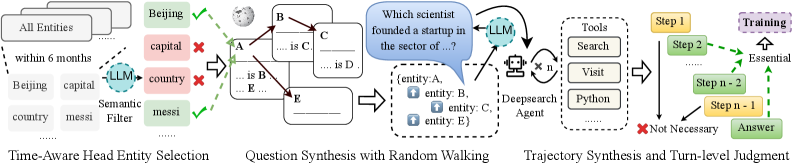
\n
## Diagram: Knowledge Graph Reasoning Pipeline
### Overview
The image depicts a three-stage pipeline for knowledge graph reasoning, utilizing Large Language Models (LLMs) and external tools. The pipeline progresses from entity selection to question synthesis and finally to trajectory synthesis for answer retrieval. The diagram illustrates the flow of information and the role of LLMs in each stage, along with feedback mechanisms and essential/non-essential steps.
### Components/Axes
The diagram is divided into three main sections, labeled:
1. "Time-Aware Head Entity Selection"
2. "Question Synthesis with Random Walking"
3. "Trajectory Synthesis and Turn-level Judgment"
Key components include:
* **Entities:** Represented as boxes labeled "All Entities", "Beijing", "entity A", "entity B", "entity C", "entity D", "entity E".
* **Relationships:** Represented as arrows connecting entities, labeled "capital", "is C", "is B", "is D".
* **LLMs:** Represented as cloud-shaped nodes labeled "LLM".
* **Tools:** Represented as rectangular nodes labeled "Tools", "Search", "Visit", "Deepsearch Agent", "Python".
* **Filters:** Represented as rectangular nodes labeled "Semantic Filter", "messi".
* **Feedback:** Represented by checkmarks (green) and crosses (red) indicating success or failure.
* **Steps:** Represented as yellow boxes labeled "Step 1", "Step 2", "Step n-1".
* **Training:** Represented as an upward arrow with the label "Essential".
* **Answer:** Represented as a box labeled "Answer".
* **Question:** Represented as a speech bubble containing the text "Which scientist founded a startup in the sector of …?".
### Detailed Analysis or Content Details
**Stage 1: Time-Aware Head Entity Selection**
* The process starts with "All Entities".
* An LLM is used to filter entities based on criteria like "within 6 months".
* The entity "Beijing" is selected.
* A relationship "capital" connects "Beijing" to "country".
* A "Semantic Filter" is applied, followed by "messi".
* Feedback is provided (green checkmark) indicating successful selection.
**Stage 2: Question Synthesis with Random Walking**
* The question "Which scientist founded a startup in the sector of …?" is generated by an LLM.
* A random walk is performed through the knowledge graph, exploring relationships between entities A, B, C, D, and E.
* Relationships "is C", "is B", and "is D" connect the entities.
* The LLM interacts with "Tools" (Search, Visit, Deepsearch Agent, Python).
**Stage 3: Trajectory Synthesis and Turn-level Judgment**
* The pipeline involves multiple steps (Step 1, Step 2, Step n-1).
* Steps are categorized as "Essential" (upward arrow) or "Not Necessary" (red cross).
* The final output is an "Answer".
### Key Observations
* The LLM plays a central role in all three stages, acting as a reasoning engine and interface to external tools.
* The pipeline incorporates a feedback mechanism to refine entity selection.
* The random walking process suggests an exploratory approach to question answering.
* The distinction between "Essential" and "Not Necessary" steps indicates a dynamic and adaptive reasoning process.
* The use of "messi" as a filter is unusual and its purpose is unclear without further context.
### Interpretation
This diagram illustrates a sophisticated knowledge graph reasoning pipeline designed to answer complex questions. The pipeline leverages the strengths of LLMs for semantic understanding and reasoning, combined with external tools for information retrieval and exploration. The random walking component suggests a method for discovering relevant information beyond direct relationships. The feedback loop and step categorization indicate a focus on efficiency and adaptability. The pipeline appears to be designed for scenarios where the answer requires traversing multiple relationships within a knowledge graph. The inclusion of "messi" as a filter is a curious element that warrants further investigation. The overall architecture suggests a system capable of handling nuanced queries and providing informed responses. The diagram is a high-level overview and does not provide details on the specific algorithms or data structures used in each stage.