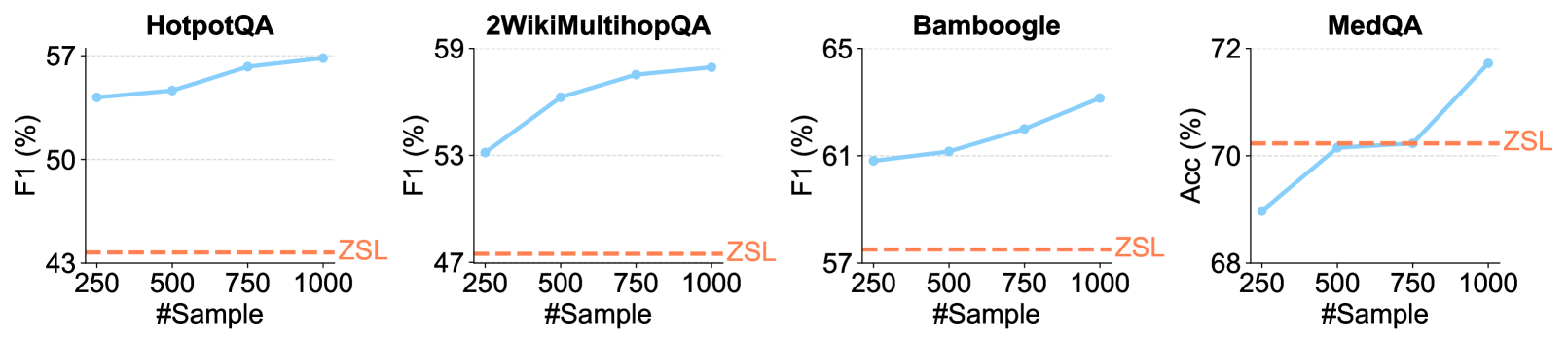
## Line Graphs: F1 Score vs. Number of Samples Across Datasets
### Overview
The image contains four line graphs comparing the F1 score (a performance metric) of different question-answering datasets (HotpotQA, 2WikiMultihopQA, Bamboogle, MedQA) as the number of training samples increases from 250 to 1000. A constant dashed red line labeled "ZSL" (Zero-Shot Learning) is present in all graphs for baseline comparison.
### Components/Axes
- **X-axis**: "#Sample" (number of training samples), ranging from 250 to 1000 in increments of 250.
- **Y-axis**: "F1 (%)" (performance metric), scaled from ~43% to ~72% depending on the dataset.
- **Legends**:
- Solid blue line: Model performance with increasing samples.
- Dashed red line: ZSL baseline (constant across all graphs).
- **Datasets**:
1. **HotpotQA**: F1 score trends.
2. **2WikiMultihopQA**: F1 score trends.
3. **Bamboogle**: F1 score trends.
4. **MedQA**: Accuracy (%) trends (note: y-axis label differs here).
### Detailed Analysis
#### HotpotQA
- **Trend**: F1 score increases steadily from ~55% (250 samples) to ~57% (1000 samples).
- **ZSL Baseline**: ~43% (constant).
#### 2WikiMultihopQA
- **Trend**: F1 score rises from ~53% (250 samples) to ~59% (1000 samples).
- **ZSL Baseline**: ~47% (constant).
#### Bamboogle
- **Trend**: F1 score grows from ~61% (250 samples) to ~65% (1000 samples).
- **ZSL Baseline**: ~57% (constant).
#### MedQA
- **Trend**: Accuracy (%) jumps from ~68% (250 samples) to ~72% (1000 samples).
- **ZSL Baseline**: ~68% (constant, matching initial accuracy).
### Key Observations
1. **Performance Gains**: All datasets show improved F1/accuracy with more samples, except MedQA, where the ZSL baseline matches the initial performance.
2. **ZSL Consistency**: The ZSL line remains flat across all datasets, indicating no improvement in zero-shot learning with additional samples.
3. **Dataset Variability**:
- MedQA achieves the highest final performance (~72%).
- HotpotQA shows the smallest improvement (~2% gain).
4. **Bamboogle Anomaly**: The ZSL baseline (~57%) is unusually high compared to other datasets, suggesting potential overlap in zero-shot capabilities.
### Interpretation
The data demonstrates that increasing training samples enhances model performance across all datasets, with MedQA benefiting most. The flat ZSL line highlights the limitation of zero-shot learning in these tasks, as it does not scale with data volume. Bamboogle’s high ZSL baseline warrants further investigation—it may indicate pre-trained knowledge transferability or dataset-specific biases. The disparity between ZSL and sample-driven performance underscores the importance of data quantity in fine-tuning models for question-answering tasks.