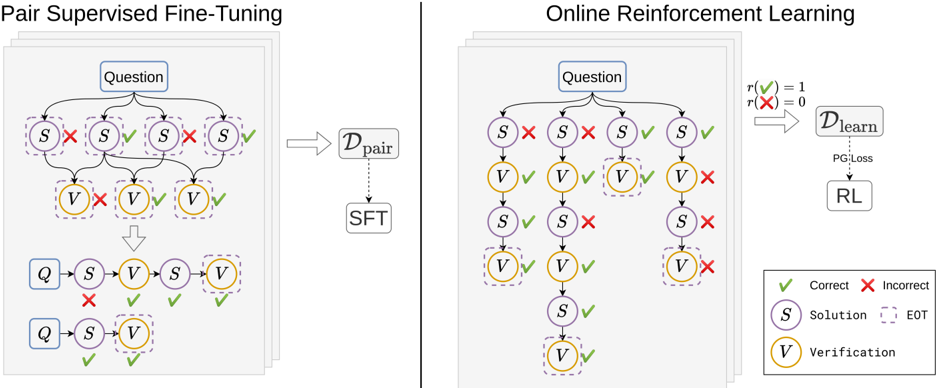
## Diagram: Pair Supervised Fine-Tuning vs. Online Reinforcement Learning
### Overview
The image presents two diagrams illustrating different approaches to training a model: Pair Supervised Fine-Tuning (left) and Online Reinforcement Learning (right). Both diagrams depict a process involving questions, solutions, and verifications, but they differ in how the model learns from these elements.
### Components/Axes
**Left Diagram (Pair Supervised Fine-Tuning):**
* **Title:** Pair Supervised Fine-Tuning
* **Nodes:**
* "Question" (top, blue rectangle)
* "S" (Solution, purple circle, dashed border)
* "V" (Verification, yellow circle, dashed border)
* "Q" (blue rectangle)
* **Dataset:** D<sub>pair</sub> (right, gray rectangle)
* **Process:** SFT (below D<sub>pair</sub>, gray rectangle)
* **Arrows:** Indicate the flow of information.
* **Checkmarks (green):** Indicate correct/positive outcomes.
* **Crosses (red):** Indicate incorrect/negative outcomes.
**Right Diagram (Online Reinforcement Learning):**
* **Title:** Online Reinforcement Learning
* **Nodes:**
* "Question" (top, blue rectangle)
* "S" (Solution, purple circle, dashed border)
* "V" (Verification, yellow circle, dashed border)
* **Reward Function:** r(✅) = 1, r(❌) = 0 (top-right)
* **Dataset:** D<sub>learn</sub> (right, gray rectangle)
* **Process:** RL (below D<sub>learn</sub>, gray rectangle)
* **Loss:** PG Loss (dotted arrow from D<sub>learn</sub> to RL)
* **Arrows:** Indicate the flow of information.
* **Checkmarks (green):** Indicate correct/positive outcomes.
* **Crosses (red):** Indicate incorrect/negative outcomes.
**Legend (bottom-right):**
* ✅ Correct
* ❌ Incorrect
* S Solution
* EOT (End of Turn, dashed border)
* V Verification
### Detailed Analysis
**Left Diagram (Pair Supervised Fine-Tuning):**
1. **Initial State:** Starts with a "Question".
2. **Solution Branching:** The "Question" leads to four possible "Solution" nodes (S). Two are marked with a red "X" (incorrect), and two are marked with a green checkmark (correct).
3. **Verification Branching:** Each "Solution" node leads to a "Verification" node (V). The first V is marked with a red "X", the next two are marked with a green checkmark.
4. **Aggregation:** The results are aggregated and fed into D<sub>pair</sub>.
5. **Fine-Tuning:** D<sub>pair</sub> is used for Supervised Fine-Tuning (SFT).
6. **Final State:** Two possible sequences of Question, Solution, Verification. One sequence has a red "X" on the Solution node, the other has green checkmarks on both Solution and Verification.
**Right Diagram (Online Reinforcement Learning):**
1. **Initial State:** Starts with a "Question".
2. **Solution Branching:** The "Question" leads to four possible "Solution" nodes (S). Two are marked with a red "X" (incorrect), and two are marked with a green checkmark (correct).
3. **Verification Branching:** Each "Solution" node leads to a "Verification" node (V). The first two V's are marked with a green checkmark, the last is marked with a red "X".
4. **Subsequent Solution and Verification:** The first two branches continue with another Solution and Verification node. The first branch has a green checkmark on the Solution and Verification. The second branch has a red "X" on the Solution and a green checkmark on the Verification.
5. **Reward Function:** The reward function assigns a value of 1 for correct actions (✅) and 0 for incorrect actions (❌).
6. **Learning:** The reward signal is used to train the model through Reinforcement Learning (RL) using Policy Gradient Loss (PG Loss) on the dataset D<sub>learn</sub>.
### Key Observations
* Both diagrams illustrate a process of question answering, where solutions are proposed and then verified.
* The key difference lies in the learning mechanism: Pair Supervised Fine-Tuning uses a pre-collected dataset of pairs, while Online Reinforcement Learning learns directly from the interaction with the environment, using a reward signal.
* The diagrams highlight the importance of both correct and incorrect examples in the learning process.
### Interpretation
The diagrams compare two distinct approaches to training a question-answering model. Pair Supervised Fine-Tuning relies on a static dataset of question-answer pairs, which may limit its ability to generalize to new or unseen scenarios. Online Reinforcement Learning, on the other hand, allows the model to learn dynamically from its interactions with the environment, potentially leading to better adaptation and performance in real-world settings. The reward function in the RL approach provides a clear signal for the model to learn from, guiding it towards correct answers and away from incorrect ones. The use of "End of Turn" (EOT) nodes suggests that the process may involve multiple turns or interactions, further emphasizing the dynamic nature of the RL approach.