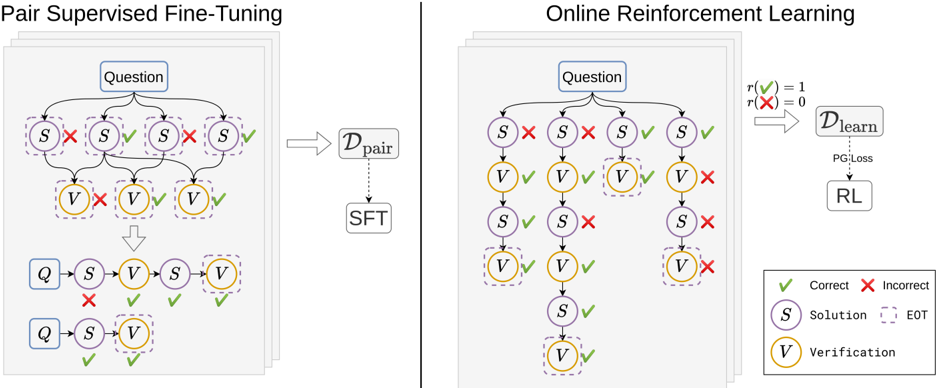
## Diagram: Pair Supervised Fine-Tuning vs. Online Reinforcement Learning
### Overview
The image compares two machine learning training paradigms: **Pair Supervised Fine-Tuning (SFT)** and **Online Reinforcement Learning (RL)**. Both processes involve iterative evaluation of solutions (S) and verifications (V) against questions (Q), with feedback loops to refine performance. The diagrams use color-coded symbols (green checkmarks for correct, red X for incorrect) to denote evaluation outcomes.
---
### Components/Axes
#### Left Diagram: Pair Supervised Fine-Tuning
- **Question (Q)**: Input prompt or problem statement.
- **Solution (S)**: Candidate answer or model output.
- **Verification (V)**: Evaluation of S against ground truth.
- **EOT (End of Turn)**: Termination marker for a training iteration.
- **D_pair**: Dataset for pair-wise comparisons.
- **SFT**: Supervised Fine-Tuning phase.
- **Legend**:
- Green checkmark (✓): Correct evaluation.
- Red X (✗): Incorrect evaluation.
#### Right Diagram: Online Reinforcement Learning
- **PG:Loss**: Policy Gradient Loss function.
- **RL**: Reinforcement Learning optimization.
- **D_learn**: Learning dataset updated via RL.
- **Legend**: Same as left diagram (✓ = Correct, ✗ = Incorrect).
---
### Detailed Analysis
#### Pair Supervised Fine-Tuning (Left)
1. **Flow**:
- A question (Q) generates multiple solution (S) and verification (V) pairs.
- Correct (✓) and incorrect (✗) evaluations are recorded.
- Data is aggregated into **D_pair**, which feeds into **SFT** for model refinement.
2. **Key Nodes**:
- Multiple S and V nodes per question, suggesting batch processing.
- Final S and V nodes are connected to **SFT**, indicating iterative improvement.
#### Online Reinforcement Learning (Right)
1. **Flow**:
- A question (Q) generates S and V pairs, with outcomes feeding into **PG:Loss**.
- **PG:Loss** drives updates to **RL**, which refines **D_learn**.
- The process includes recursive evaluation (e.g., S → V → S → V loops).
2. **Key Nodes**:
- **PG:Loss** acts as a feedback mechanism, optimizing **RL**.
- **D_learn** is dynamically updated, unlike the static **D_pair** in SFT.
---
### Key Observations
1. **Structural Differences**:
- SFT uses a static dataset (**D_pair**) with fixed evaluations.
- RL employs a dynamic dataset (**D_learn**) updated via continuous feedback.
2. **Evaluation Outcomes**:
- Both diagrams show mixed correctness (✓/✗) across S and V nodes, indicating iterative refinement.
3. **EOT vs. PG:Loss**:
- EOT marks the end of a training cycle in SFT.
- PG:Loss in RL quantifies the gradient for policy updates, enabling real-time learning.
---
### Interpretation
- **Pair Supervised Fine-Tuning** emphasizes batch-based correction, where multiple S/V pairs are evaluated before updating the model. This aligns with traditional supervised learning but lacks adaptability to new data.
- **Online Reinforcement Learning** introduces a dynamic, self-improving loop where **PG:Loss** directly influences **RL**, allowing the model to adapt to new questions and evaluation outcomes in real time. The recursive S/V loops suggest a focus on long-term reward maximization.
- **Notable Anomalies**: The left diagram’s EOT implies a fixed training horizon, while the right diagram’s recursive flow suggests unbounded learning. This highlights a trade-off between stability (SFT) and adaptability (RL).
The diagrams illustrate complementary approaches: SFT for foundational training and RL for continuous, context-aware optimization.