\n
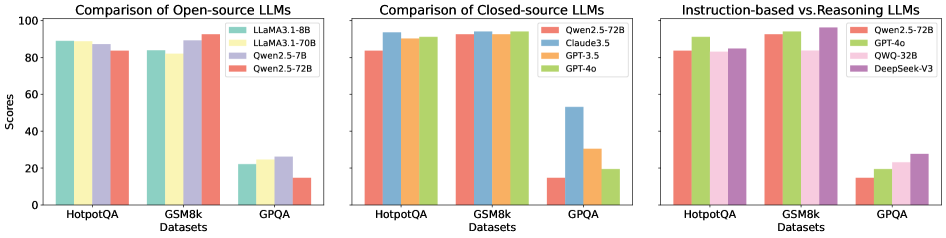
## [Multi-Panel Bar Chart]: Performance Comparison of Large Language Models (LLMs)
### Overview
The image displays three adjacent bar charts comparing the performance scores of various Large Language Models (LLMs) across three benchmark datasets: HotpotQA, GSM8k, and GPQA. The charts are segmented by model type: open-source, closed-source, and a comparison of instruction-based versus reasoning-focused models. All charts share the same y-axis scale ("Scores" from 0 to 100) and x-axis categories (the three datasets).
### Components/Axes
* **Chart 1 (Left):** Title: "Comparison of Open-source LLMs".
* **X-axis Label:** "Datasets"
* **X-axis Categories:** "HotpotQA", "GSM8k", "GPQA"
* **Y-axis Label:** "Scores"
* **Y-axis Scale:** 0, 20, 40, 60, 80, 100
* **Legend (Top-Right):** Four models, each with a distinct color:
* LLaMA3.1-8B (Teal)
* LLaMA3.1-70B (Light Yellow)
* Qwen2.5-7B (Light Purple)
* Qwen2.5-72B (Salmon/Red)
* **Chart 2 (Center):** Title: "Comparison of Closed-source LLMs".
* **X-axis Label:** "Datasets"
* **X-axis Categories:** "HotpotQA", "GSM8k", "GPQA"
* **Y-axis Label:** "Scores" (implied from left chart)
* **Legend (Top-Right):** Four models:
* Qwen2.5-72B (Salmon/Red)
* Claude3.5 (Blue)
* GPT-3.5 (Orange)
* GPT-4o (Green)
* **Chart 3 (Right):** Title: "Instruction-based vs Reasoning LLMs".
* **X-axis Label:** "Datasets"
* **X-axis Categories:** "HotpotQA", "GSM8k", "GPQA"
* **Y-axis Label:** "Scores" (implied from left chart)
* **Legend (Top-Right):** Four models:
* Qwen2.5-72B (Salmon/Red)
* GPT-4o (Green)
* QWQ-32B (Pink)
* DeepSeek-V3 (Purple)
### Detailed Analysis
**Chart 1: Open-source LLMs**
* **HotpotQA:** All four models score very similarly, clustered tightly around approximately 85-90.
* **GSM8k:** Performance remains high and consistent across models, again in the ~85-90 range.
* **GPQA:** A significant performance drop is observed for all models. Scores range from approximately 15 (Qwen2.5-72B) to 25 (Qwen2.5-7B). This dataset appears substantially more challenging for these open-source models.
**Chart 2: Closed-source LLMs**
* **HotpotQA:** GPT-4o (Green) leads with a score near 95. Claude3.5 (Blue) and Qwen2.5-72B (Salmon) are close behind (~90). GPT-3.5 (Orange) scores slightly lower (~85).
* **GSM8k:** GPT-4o again leads (~95). Claude3.5 and Qwen2.5-72B are very close (~90-92). GPT-3.5 is slightly lower (~88).
* **GPQA:** A dramatic drop in scores occurs. GPT-4o maintains the highest score (~55). Claude3.5 scores ~30. GPT-3.5 scores ~20. Qwen2.5-72B (Salmon) scores the lowest, approximately 15.
**Chart 3: Instruction-based vs Reasoning LLMs**
* **HotpotQA:** GPT-4o (Green) leads (~95). DeepSeek-V3 (Purple) is very close (~92). Qwen2.5-72B (Salmon) and QWQ-32B (Pink) score ~85-88.
* **GSM8k:** GPT-4o leads (~95). DeepSeek-V3 is again very close (~93). Qwen2.5-72B and QWQ-32B score ~88-90.
* **GPQA:** DeepSeek-V3 (Purple) shows the strongest performance among this group, scoring approximately 30. QWQ-32B (Pink) scores ~25. GPT-4o (Green) scores ~20. Qwen2.5-72B (Salmon) scores the lowest, ~15.
### Key Observations
1. **Dataset Difficulty:** GPQA is consistently the most challenging benchmark for all model categories, causing a universal and significant drop in scores compared to HotpotQA and GSM8k.
2. **Model Leadership:** GPT-4o (Green) is the top performer in the closed-source and instruction/reasoning comparisons on the two easier datasets (HotpotQA, GSM8k).
3. **Open-source vs. Closed-source Gap:** On the harder GPQA dataset, the top closed-source model (GPT-4o, ~55) significantly outperforms the top open-source model (Qwen2.5-7B, ~25).
4. **Specialized Performance:** In the third chart, DeepSeek-V3 (Purple), a reasoning-focused model, achieves the highest score on the challenging GPQA dataset (~30), outperforming the general-purpose GPT-4o (~20) on that specific task.
5. **Scale Matters (Open-source):** Within the open-source chart, the larger 70B/72B parameter models (LLaMA3.1-70B, Qwen2.5-72B) do not consistently outperform their smaller 8B/7B counterparts across all datasets, suggesting task-specific optimization may be as important as scale.
### Interpretation
This comparative analysis reveals several key insights into the current LLM landscape:
* **Benchmark Sensitivity:** Model performance is highly dependent on the evaluation benchmark. Models that excel on knowledge-intensive (HotpotQA) or mathematical (GSM8k) tasks may struggle on more complex reasoning or specialized knowledge tasks (GPQA).
* **The State of the Art:** GPT-4o represents a high-water mark for general performance across common benchmarks. However, its advantage narrows or disappears on the most difficult tasks, where specialized models like DeepSeek-V3 can show superior capability.
* **Open-source Progress and Limits:** Open-source models have achieved near parity with closed-source models on certain standard benchmarks (HotpotQA, GSM8k). However, a substantial performance gap remains on the most challenging evaluations (GPQA), indicating that the most advanced reasoning or knowledge synthesis capabilities may still be concentrated in proprietary systems.
* **Strategic Model Selection:** The data suggests that choosing an LLM requires careful consideration of the target task. For general use, a model like GPT-4o is strong. For specialized reasoning on hard problems, a model like DeepSeek-V3 might be preferable. For cost-effective deployment on standard tasks, a capable open-source model like Qwen2.5-7B could be sufficient.