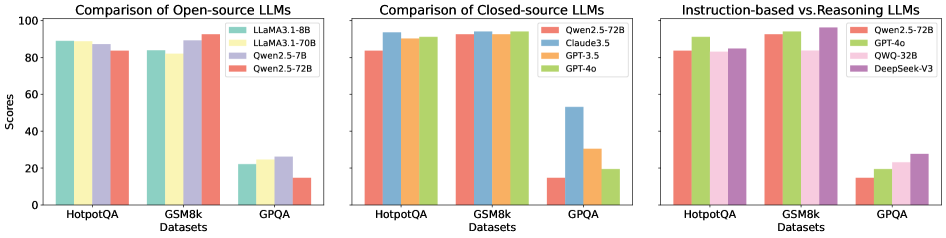
## Bar Chart: Comparison of LLMs Across Datasets
### Overview
The image presents a comparative bar chart analyzing the performance of various large language models (LLMs) across three datasets: HotpotQA, GSM8k, and GPQA. The chart is divided into three sections:
1. **Open-source LLMs**
2. **Closed-source LLMs**
3. **Instruction-based vs. Reasoning LLMs**
Each section compares model performance using scores (0–100) on the y-axis, with datasets on the x-axis.
---
### Components/Axes
- **X-axis (Datasets)**:
- HotpotQA (leftmost)
- GSM8k (middle)
- GPQA (rightmost)
- **Y-axis (Scores)**: Ranges from 0 to 100 in increments of 20.
- **Legends**:
- **Open-source LLMs**:
- LLaMA3.1-8B (teal)
- LLaMA3.1-70B (yellow)
- Qwen2.5-72B (purple)
- **Closed-source LLMs**:
- Qwen2.5-72B (red)
- Claude3.5 (blue)
- GPT-3.5 (orange)
- GPT-4o (green)
- **Instruction-based vs. Reasoning LLMs**:
- Qwen2.5-72B (red)
- GPT-4o (green)
- QWQ-32B (pink)
- DeepSeek-V3 (purple)
---
### Detailed Analysis
#### Open-source LLMs
- **HotpotQA**:
- LLaMA3.1-8B: ~88
- LLaMA3.1-70B: ~87
- Qwen2.5-72B: ~85
- **GSM8k**:
- LLaMA3.1-8B: ~83
- LLaMA3.1-70B: ~86
- Qwen2.5-72B: ~90
- **GPQA**:
- LLaMA3.1-8B: ~22
- LLaMA3.1-70B: ~24
- Qwen2.5-72B: ~15
#### Closed-source LLMs
- **HotpotQA**:
- Qwen2.5-72B: ~83
- Claude3.5: ~92
- GPT-3.5: ~91
- GPT-4o: ~90
- **GSM8k**:
- Qwen2.5-72B: ~90
- Claude3.5: ~93
- GPT-3.5: ~92
- GPT-4o: ~91
- **GPQA**:
- Qwen2.5-72B: ~15
- Claude3.5: ~53
- GPT-3.5: ~30
- GPT-4o: ~20
#### Instruction-based vs. Reasoning LLMs
- **HotpotQA**:
- Qwen2.5-72B: ~83
- GPT-4o: ~90
- QWQ-32B: ~85
- DeepSeek-V3: ~88
- **GSM8k**:
- Qwen2.5-72B: ~90
- GPT-4o: ~93
- QWQ-32B: ~87
- DeepSeek-V3: ~95
- **GPQA**:
- Qwen2.5-72B: ~15
- GPT-4o: ~20
- QWQ-32B: ~22
- DeepSeek-V3: ~27
---
### Key Observations
1. **Open-source LLMs**:
- Perform well on **HotpotQA** and **GSM8k** (scores >80), but struggle on **GPQA** (scores <25).
- Larger models (LLaMA3.1-70B) slightly outperform smaller ones (LLaMA3.1-8B) in HotpotQA and GSM8k.
2. **Closed-source LLMs**:
- Dominate all datasets, with scores >85 on HotpotQA/GSM8k and >50 on GPQA.
- GPT-4o and Claude3.5 consistently lead in GPQA (53 and 30, respectively).
3. **Instruction-based vs. Reasoning LLMs**:
- **Reasoning models** (DeepSeek-V3) outperform instruction-based models (QWQ-32B) on GPQA (27 vs. 22).
- DeepSeek-V3 achieves the highest scores across all datasets (95 on GSM8k).
---
### Interpretation
- **Closed-source models** (e.g., GPT-4o, Claude3.5) demonstrate superior performance, particularly on complex reasoning tasks (GPQA), suggesting better optimization for such tasks.
- **Open-source models** (LLaMA, Qwen) lag in GPQA, indicating potential limitations in handling multi-step reasoning.
- **Instruction-based models** (QWQ-32B) underperform compared to reasoning-focused models (DeepSeek-V3), highlighting the importance of architectural design for reasoning tasks.
- **GPQA** acts as a bottleneck for all models, with scores dropping by ~60–70% compared to HotpotQA/GSM8k, underscoring its difficulty.
This analysis suggests that closed-source and reasoning-optimized models are more reliable for complex tasks, while open-source models may require further tuning for specialized applications.