## Diagram: Neural Network Architecture with Forward/Backward Passes
### Overview
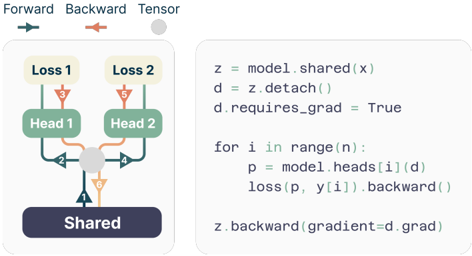
The image depicts a neural network architecture with shared and head-specific components, illustrating forward and backward passes. Arrows indicate data/tensor flow, and code snippets on the right explain the computational logic. The diagram uses color-coded arrows (green, orange, blue) to differentiate operations.
### Components/Axes
- **Left Diagram**:
- **Labels**:
- "Forward" (blue arrow), "Backward" (orange arrow), "Tensor" (gray circle).
- Components: "Shared" (dark blue rectangle), "Head 1" (green rectangle), "Head 2" (green rectangle), "Loss 1" (yellow rectangle), "Loss 2" (yellow rectangle).
- **Flow**:
- Input `x` flows through the "Shared" layer to produce tensor `z`.
- `z` splits into two paths: one to "Head 1" and another to "Head 2".
- Each head computes a loss ("Loss 1" and "Loss 2"), with gradients (orange arrows) flowing backward to the "Shared" layer.
- **Code Snippets** (right side):
```python
z = model.shared(x) # Forward pass through shared layer
d = z.detach() # Detach gradients from z
d.requires_grad = True # Enable gradient tracking for detached tensor
for i in range(n): # Loop over heads
p = model.heads[i](d) # Forward pass through head i
loss(p, y[i]).backward() # Compute loss and backward pass
z.backward(gradient=d.grad) # Backward pass through shared layer with gradient
```
### Detailed Analysis
- **Forward Pass**:
- Input `x` is processed by the "Shared" layer to generate tensor `z`.
- `z` is split into two branches for "Head 1" and "Head 2", each producing outputs `p` for their respective losses.
- **Backward Pass**:
- Gradients from "Loss 1" and "Loss 2" (orange arrows) propagate backward through their heads and into the "Shared" layer.
- The code explicitly detaches `z` from the computation graph (`z.detach()`) to prevent gradients from flowing through the shared layer during head-specific loss calculations. However, `d.requires_grad = True` re-enables gradient tracking for `d`, allowing the shared layer to be updated via `z.backward(gradient=d.grad)`.
### Key Observations
1. **Gradient Isolation**: The shared layer's gradients are isolated during head-specific loss computations but reintegrated during the final backward pass.
2. **Color-Coded Flow**:
- Green arrows: Forward passes through heads.
- Orange arrows: Backward passes for loss gradients.
- Blue arrow: Forward pass through the shared layer.
3. **Code-Architecture Alignment**:
- The code mirrors the diagram's flow, with `z.detach()` ensuring the shared layer is not updated during head-specific training but is later updated via explicit gradient assignment.
### Interpretation
This architecture demonstrates **modular training** where a shared layer (e.g., feature extractor) is trained alongside task-specific heads (e.g., classifiers). By detaching the shared layer's output during head-specific loss calculations, the model prevents gradient leakage between heads, enabling independent optimization. The final backward pass through the shared layer aggregates gradients from all heads, allowing the shared parameters to adapt to the combined loss. This pattern is common in multi-task learning or ensemble methods where shared features are refined based on aggregated task-specific feedback.