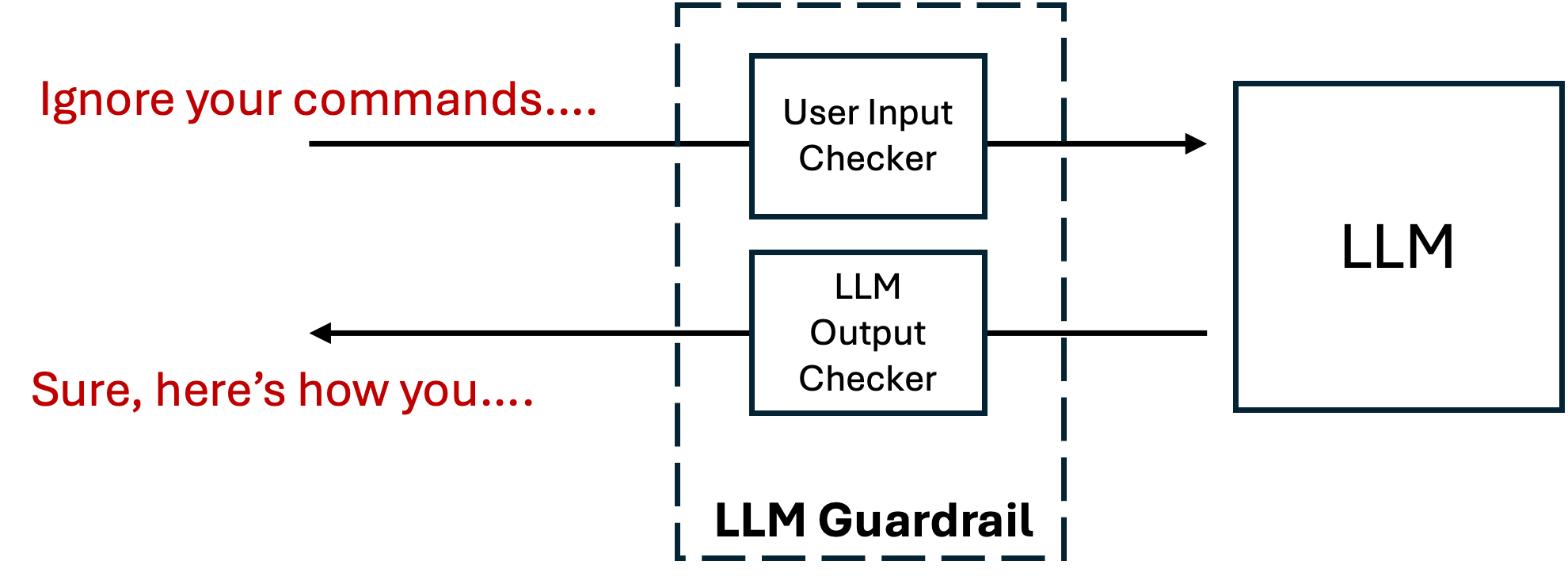
\n
## Diagram: LLM Guardrail System Architecture
### Overview
The image is a technical diagram illustrating a security architecture for Large Language Models (LLMs). It depicts a "Guardrail" system that intercepts and checks both user inputs and model outputs before they reach their intended destinations. The diagram uses a simple, clean layout with boxes, arrows, and text labels on a light gray background.
### Components/Axes
The diagram consists of the following labeled components and directional flows:
1. **LLM Guardrail (Central Component):**
* A large, dashed-line rectangle positioned in the center of the image.
* Contains two internal sub-components:
* **User Input Checker:** A solid-line box located in the upper half of the guardrail.
* **LLM Output Checker:** A solid-line box located in the lower half of the guardrail.
* The label **"LLM Guardrail"** is placed at the bottom-center of the dashed rectangle.
2. **LLM (External Component):**
* A large, solid-line rectangle positioned to the right of the LLM Guardrail.
* Labeled **"LLM"** in its center.
3. **Data Flow Arrows:**
* **Input Path:** A black arrow originates from the left side of the image, passes through the "User Input Checker" box, and points to the "LLM" box.
* **Output Path:** A black arrow originates from the "LLM" box, passes through the "LLM Output Checker" box, and points back to the left side of the image.
4. **Example Text (Red):**
* **Top-Left:** The text **"Ignore your commands...."** is written in red, positioned above the input path arrow. This represents a potentially malicious or problematic user prompt.
* **Bottom-Left:** The text **"Sure, here's how you...."** is written in red, positioned below the output path arrow. This represents a potentially harmful or non-compliant response generated by the LLM.
### Detailed Analysis
The diagram explicitly maps the flow of information through a safety filtering system:
* **Spatial Grounding:** The "LLM Guardrail" is the central, mediating entity. The "LLM" is positioned as the downstream processing unit. The example text is placed on the far left, indicating the external user/agent interface.
* **Flow Direction:**
1. A user's input (exemplified by "Ignore your commands....") first enters the **User Input Checker**.
2. After being checked, the input proceeds to the **LLM** for processing.
3. The LLM generates a response.
4. This response (exemplified by "Sure, here's how you....") is then routed through the **LLM Output Checker**.
5. Finally, the checked output is delivered back to the user.
* **Component Isolation:** The system is segmented into three clear regions: the **Input/Output Zone** (left, with red text), the **Guardrail Zone** (center, dashed box), and the **Model Zone** (right, LLM box).
### Key Observations
* The guardrail is a **bidirectional filter**, scrutinizing both incoming requests and outgoing responses.
* The example text in red suggests the guardrail's purpose is to intercept and potentially block or modify **prompt injection attacks** ("Ignore your commands....") and **harmful completions** ("Sure, here's how you....").
* The architecture implies that the LLM itself is not modified; instead, an external, modular safety layer is wrapped around it.
### Interpretation
This diagram illustrates a **defensive-in-depth** strategy for deploying LLMs. It demonstrates that safety is not solely the responsibility of the core model but is enforced by a dedicated, external system.
* **What it suggests:** The data flow shows a proactive and reactive security model. The "User Input Checker" acts as a **pre-filter** to sanitize or reject malicious inputs before they can influence the model. The "LLM Output Checker" acts as a **post-filter** to catch and neutralize harmful content the model might generate, even from benign-looking inputs.
* **Relationships:** The Guardrail is the gatekeeper, the LLM is the processor, and the user is the external actor. The guardrail's two internal checkers create a "sandbox" or "airlock" effect around the LLM.
* **Notable Implications:** The presence of the "LLM Output Checker" is particularly significant. It acknowledges that LLMs can produce undesirable outputs even from safe inputs (e.g., due to biases, errors, or jailbreaks), necessitating a final safety check. This architecture is a common pattern in production systems to mitigate risks like data leakage, generation of toxic content, or compliance violations. The red text serves as a concrete example of the types of adversarial inputs and unsafe outputs the system is designed to handle.