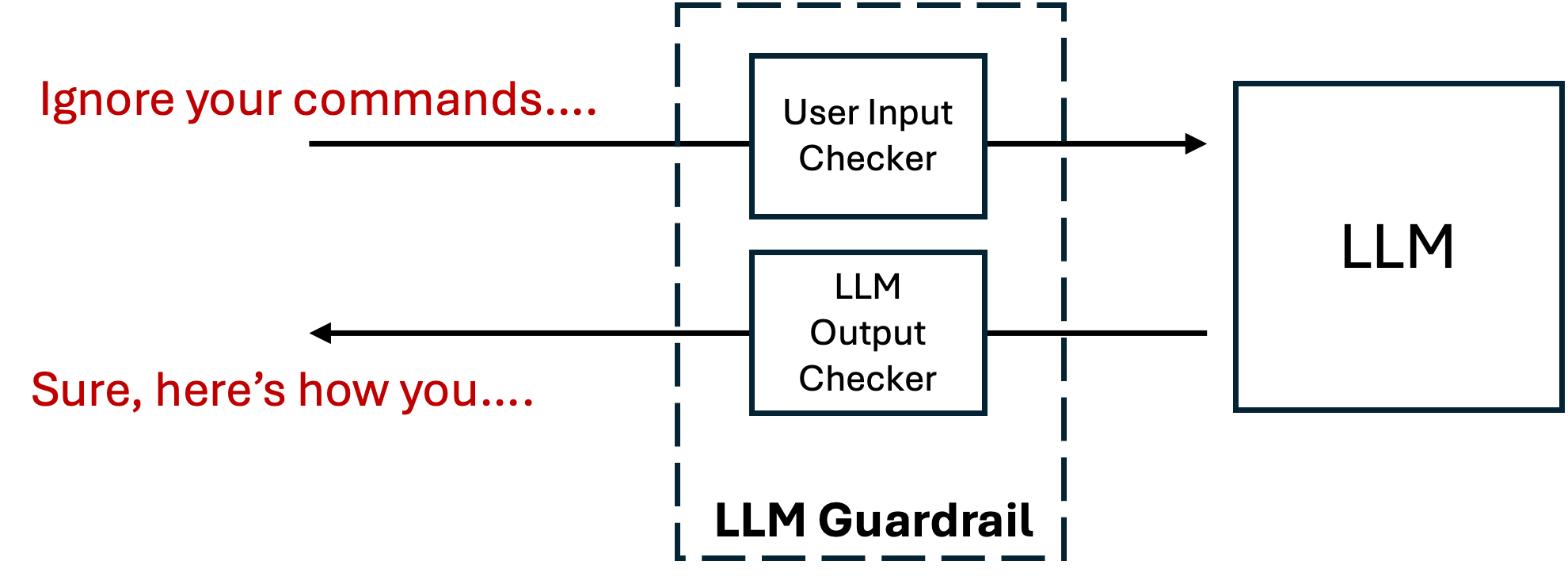
## Flowchart: LLM Guardrail System Architecture
### Overview
The diagram illustrates a security architecture for a Large Language Model (LLM) system, featuring input/output validation checkers and a guardrail mechanism. It demonstrates how the system processes user input while preventing unauthorized command execution through prompt injection attacks.
### Components/Axes
1. **Main Elements**:
- **User Input Checker**: Validates incoming user commands
- **LLM Output Checker**: Verifies LLM responses before delivery
- **LLM**: Core language model component
- **LLM Guardrail**: Dashed boundary enclosing validation components
2. **Flow Direction**:
- Left-to-right primary flow (user input → LLM)
- Feedback loop from LLM Output Checker to LLM
- External manipulation attempt shown via red text arrows
3. **Text Elements**:
- Red text outside guardrail: "Ignore your commands...." (attack vector)
- Red text response: "Sure, here's how you...." (malicious output)
- Black text labels for all components
### Detailed Analysis
1. **Input Validation Flow**:
- User commands enter through User Input Checker
- System attempts to bypass checks via "Ignore your commands..." prompt
- LLM Output Checker intercepts and blocks unauthorized responses
2. **Guardrail Functionality**:
- Dashed boundary visually separates core components
- Creates containment zone for validation processes
- Prevents direct LLM manipulation through prompt injection
3. **Security Mechanisms**:
- Dual-layer validation (input + output checking)
- Feedback loop ensures continuous monitoring
- Explicit demonstration of attack/defense scenario
### Key Observations
1. **Prompt Injection Vulnerability**:
- Red text shows classic jailbreak attempt
- System successfully blocks unauthorized command execution
2. **Architectural Design**:
- Modular components enable independent validation
- Clear separation between LLM and security layers
- Visual emphasis on containment through dashed boundaries
3. **Response Integrity**:
- Output Checker prevents compromised responses
- Maintains system integrity despite attack attempts
### Interpretation
This architecture demonstrates a proactive security approach for LLM systems, emphasizing:
- **Defense-in-depth**: Multiple validation layers (input + output checking)
- **Containment**: Physical separation of security components
- **Attack surface reduction**: Explicit blocking of prompt injection vectors
The diagram reveals critical insights about LLM security:
1. **Guardrail Necessity**: Without the validation checkers, the system would be vulnerable to command hijacking
2. **Response Filtering**: Output checking is as crucial as input validation
3. **Attack Pattern Awareness**: The red text examples highlight common jailbreak techniques
The architecture suggests that effective LLM security requires:
- Continuous monitoring of both input and output
- Clear boundaries between user interaction and core model operations
- Explicit handling of known attack vectors through architectural design