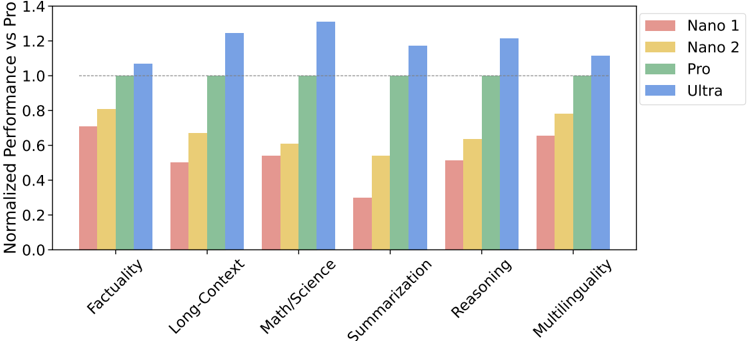
## Bar Chart: Normalized Performance vs Pro
### Overview
The chart compares the normalized performance of four AI models (Nano 1, Nano 2, Pro, Ultra) across six evaluation categories: Factuality, Long-Context, Math/Science, Summarization, Reasoning, and Multilinguality. Performance is measured relative to a "Pro" benchmark (green bars), with values normalized to a scale of 0.0–1.4.
### Components/Axes
- **X-axis**: Evaluation categories (Factuality, Long-Context, Math/Science, Summarization, Reasoning, Multilinguality).
- **Y-axis**: Normalized performance (0.0–1.4), with a dashed line at 1.0 representing the "Pro" baseline.
- **Legend**: Located in the top-right corner, mapping colors to models:
- Red: Nano 1
- Yellow: Nano 2
- Green: Pro
- Blue: Ultra
### Detailed Analysis
1. **Factuality**:
- Nano 1: ~0.7
- Nano 2: ~0.8
- Pro: 1.0
- Ultra: ~1.05
2. **Long-Context**:
- Nano 1: ~0.5
- Nano 2: ~0.7
- Pro: 1.0
- Ultra: ~1.25
3. **Math/Science**:
- Nano 1: ~0.55
- Nano 2: ~0.6
- Pro: 1.0
- Ultra: ~1.3
4. **Summarization**:
- Nano 1: ~0.3
- Nano 2: ~0.55
- Pro: 1.0
- Ultra: ~1.15
5. **Reasoning**:
- Nano 1: ~0.5
- Nano 2: ~0.65
- Pro: 1.0
- Ultra: ~1.2
6. **Multilinguality**:
- Nano 1: ~0.65
- Nano 2: ~0.8
- Pro: 1.0
- Ultra: ~1.1
### Key Observations
- **Pro Baseline**: All "Pro" bars are fixed at 1.0, serving as the reference point.
- **Ultra Performance**: Consistently outperforms other models, peaking at ~1.3 in Math/Science.
- **Nano 1 Weakness**: Struggles in Summarization (~0.3) and Reasoning (~0.5).
- **Nano 2 Consistency**: Outperforms Nano 1 in most categories but remains below Pro/Ultra.
- **Ultra Decline**: Performance drops slightly in Multilinguality (~1.1) compared to Math/Science (~1.3).
### Interpretation
The chart highlights trade-offs between model complexity and task-specific performance:
- **Ultra** excels in technical domains (Math/Science, Reasoning) but shows reduced capability in Multilinguality, suggesting potential over-optimization for structured tasks.
- **Nano models** underperform across all categories, with Nano 1 being particularly weak in Summarization. This may indicate architectural limitations in handling abstract or generative tasks.
- **Pro** serves as a stable benchmark, with all models falling short except Ultra in specific areas. The gap between Nano/Ultra and Pro underscores the importance of model scale in achieving human-level performance.
- The ~15% performance drop in Ultra for Multilinguality hints at potential resource allocation biases toward technical over linguistic tasks.