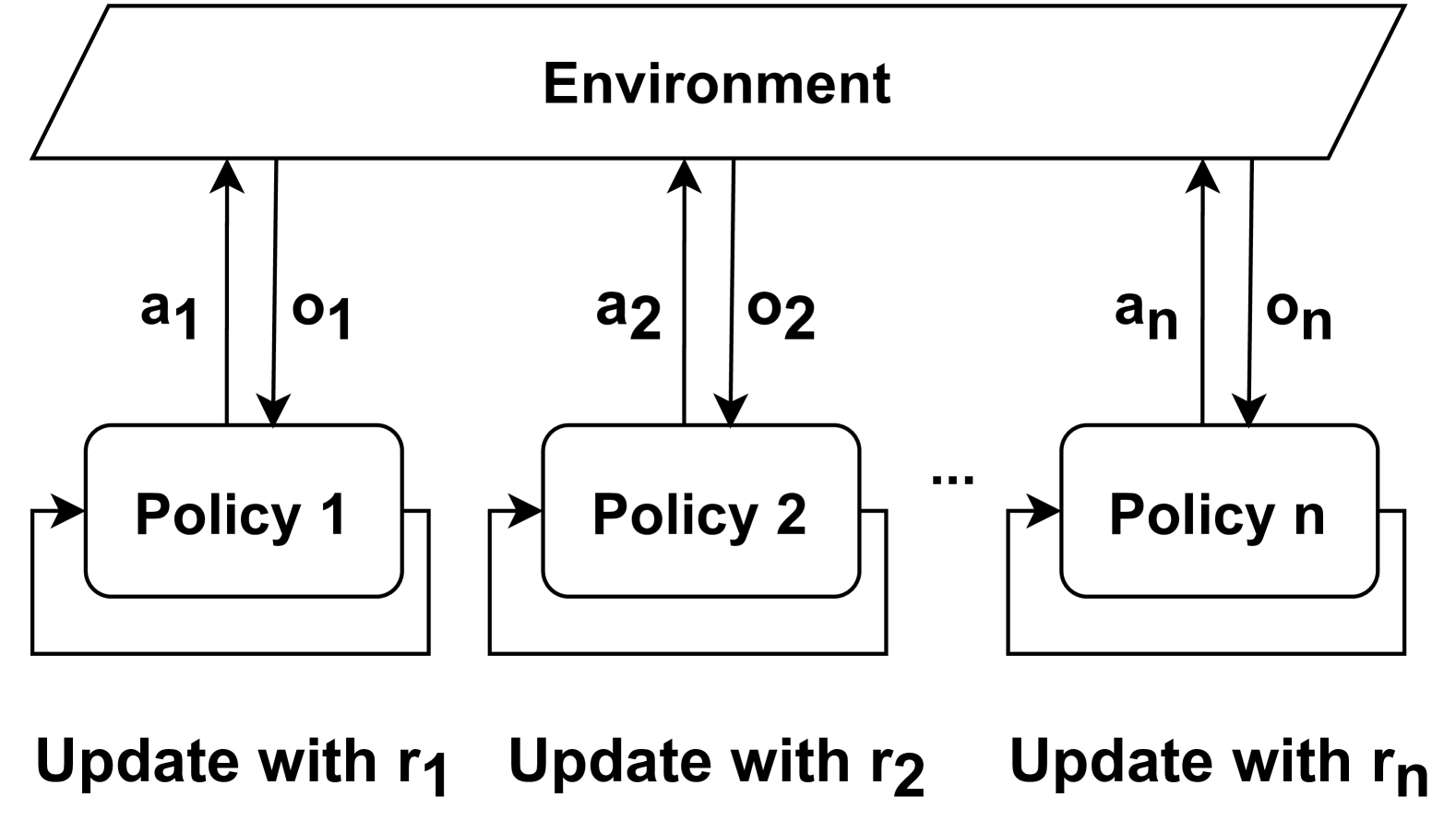
## Reinforcement Learning Diagram: Multi-Policy Environment Interaction
### Overview
The image is a diagram illustrating the interaction between an environment and multiple policies in a reinforcement learning setting. It shows how each policy interacts with the environment, receives observations, and is updated based on rewards.
### Components/Axes
* **Environment:** A rectangular box at the top of the diagram, labeled "Environment".
* **Policies:** Three rounded rectangles labeled "Policy 1", "Policy 2", and "Policy n". There is an ellipsis (...) between Policy 2 and Policy n, indicating that there can be multiple policies.
* **Actions:** Arrows pointing upwards from each policy to the environment, labeled "a1", "a2", and "an" respectively. These represent the actions taken by each policy.
* **Observations:** Arrows pointing downwards from the environment to each policy, labeled "o1", "o2", and "on" respectively. These represent the observations received by each policy.
* **Update Mechanism:** Arrows looping from the output of each policy back to its input, indicating an update mechanism.
* **Rewards:** Text labels below each policy, indicating that the policies are updated with rewards: "Update with r1", "Update with r2", and "Update with rn".
### Detailed Analysis
* **Environment:** The environment is the source of observations and the recipient of actions.
* **Policy 1:** Takes action "a1", receives observation "o1", and is updated with reward "r1".
* **Policy 2:** Takes action "a2", receives observation "o2", and is updated with reward "r2".
* **Policy n:** Takes action "an", receives observation "on", and is updated with reward "rn".
* **Ellipsis (...):** Indicates that there can be any number of policies between Policy 2 and Policy n.
* **Flow:** The diagram shows a cyclical flow of information: Policies take actions, the environment provides observations, and the policies are updated based on rewards.
### Key Observations
* The diagram illustrates a multi-agent or multi-policy reinforcement learning scenario.
* Each policy interacts with the environment independently.
* The rewards received by each policy are used to update its behavior.
### Interpretation
The diagram represents a system where multiple independent policies interact with a shared environment. Each policy learns and adapts based on its own actions, observations, and rewards. This setup could be used in various applications, such as training multiple robots to perform different tasks in the same environment, or optimizing different aspects of a complex system. The use of individual reward signals (r1, r2, ..., rn) suggests that each policy has its own specific objective or goal.