\n
## Diagram: Policy Iteration/Interaction with Environment
### Overview
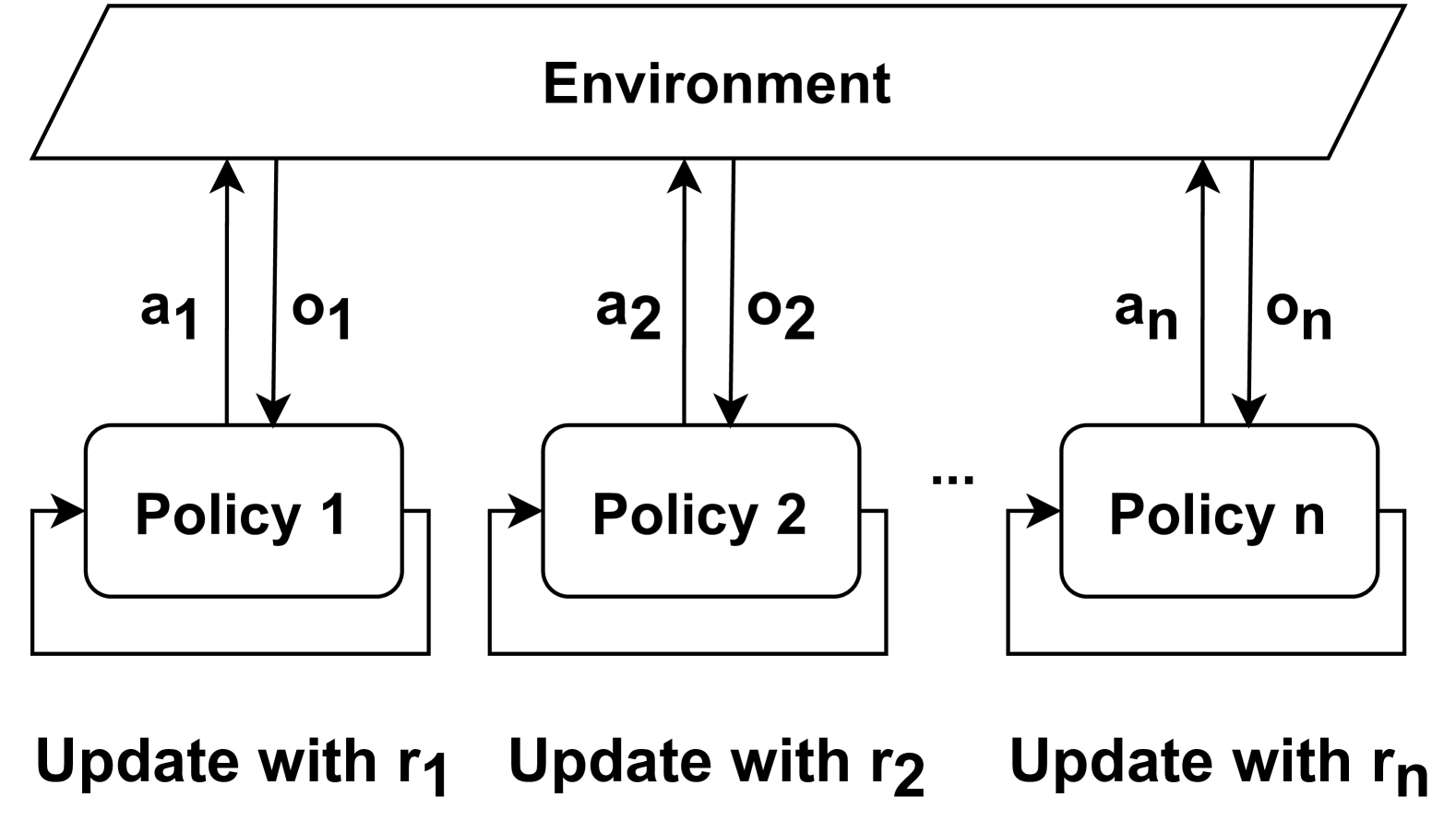
The image depicts a diagram illustrating the interaction between multiple policies and an environment. It shows a series of 'Policy' blocks interacting with a larger 'Environment' block, with actions taken and observations received. The diagram suggests an iterative or parallel process of policy evaluation and update.
### Components/Axes
The diagram consists of the following components:
* **Environment:** A large, grey rectangular block at the top of the diagram.
* **Policy 1, Policy 2, ... Policy n:** A series of rounded rectangular blocks arranged horizontally below the 'Environment' block.
* **a1, a2, ... an:** Labels indicating actions taken by each policy, pointing from the 'Policy' blocks to the 'Environment' block.
* **o1, o2, ... on:** Labels indicating observations received from the 'Environment' block, pointing from the 'Environment' block to the 'Policy' blocks.
* **r1, r2, ... rn:** Labels indicating rewards or updates received by each policy, pointing from the 'Policy' blocks.
* **"...":** An ellipsis indicating that the pattern of 'Policy' blocks continues beyond 'Policy 2'.
### Detailed Analysis or Content Details
The diagram shows a sequence of interactions. Each 'Policy' block (Policy 1 through Policy n) takes an action (a1 through an) which affects the 'Environment'. The 'Environment' then provides an observation (o1 through on) back to the corresponding 'Policy'. Finally, each 'Policy' is updated with a reward or signal (r1 through rn).
The diagram suggests a parallel process, where multiple policies are simultaneously interacting with the environment. The ellipsis indicates that this process can be extended to an arbitrary number of policies.
### Key Observations
* The diagram emphasizes the cyclical nature of policy-environment interaction.
* The use of 'n' suggests a generalized representation applicable to any number of policies.
* The diagram does not specify the nature of the actions, observations, or rewards.
* The diagram does not specify the method of updating the policies with the rewards.
### Interpretation
This diagram likely represents a reinforcement learning scenario, specifically a model of policy iteration or policy interaction with an environment. The 'Environment' represents the world in which the policies operate, and the 'Policies' represent agents attempting to learn optimal behavior. The actions (a1-an) are the choices made by the policies, the observations (o1-on) are the feedback received from the environment, and the rewards (r1-rn) are signals used to improve the policies.
The diagram highlights the core loop of reinforcement learning: an agent takes an action, observes the result, and updates its policy based on the reward received. The parallel arrangement of policies suggests that multiple agents might be learning simultaneously, potentially through techniques like multi-agent reinforcement learning or ensemble methods. The diagram is abstract and does not provide specific details about the learning algorithm or the environment's dynamics. It serves as a high-level conceptual illustration of the interaction between policies and an environment.