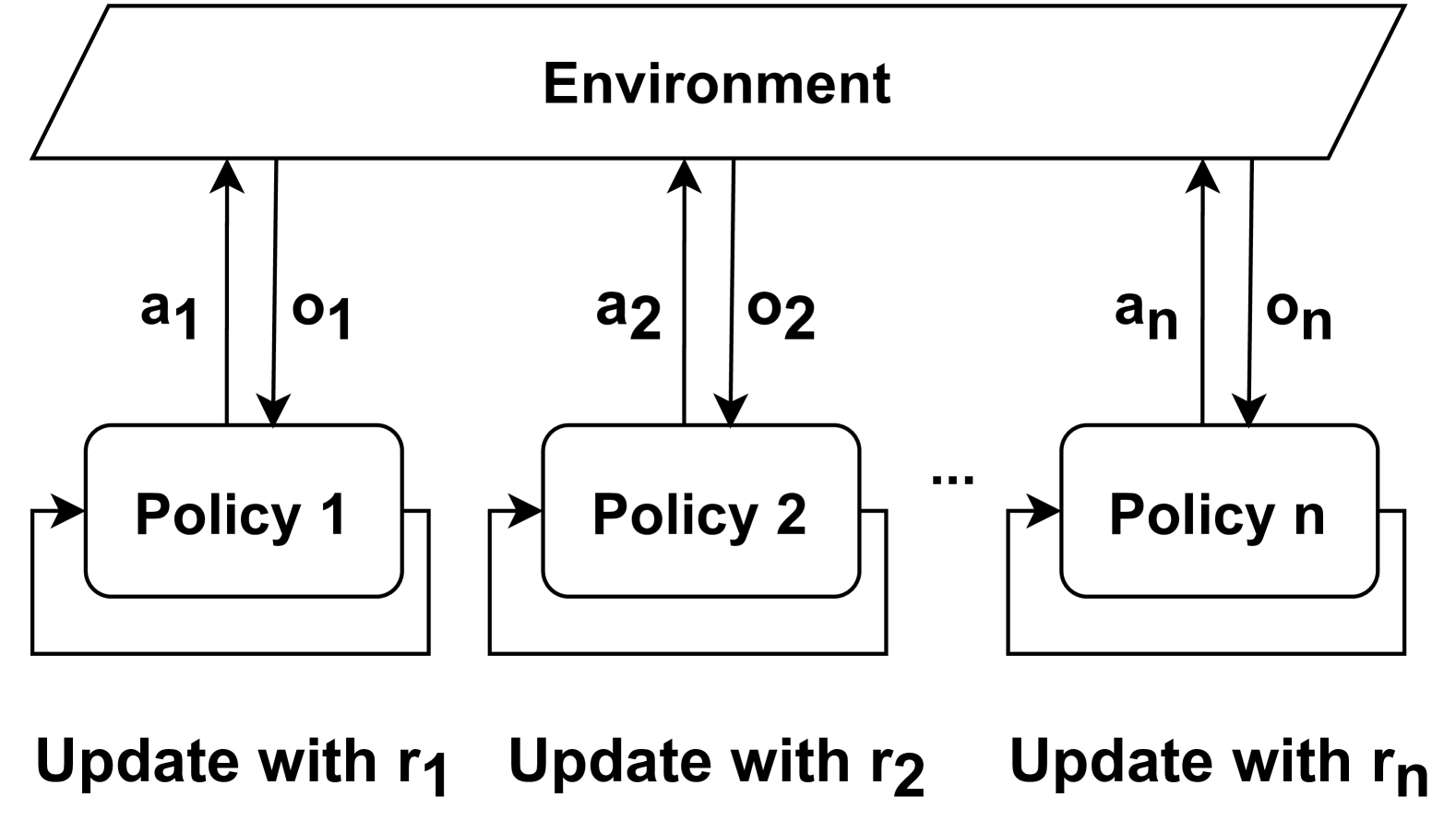
## Diagram: Reinforcement Learning Policy-Environment Interaction System
### Overview
The diagram illustrates a multi-policy reinforcement learning system where multiple policies (Policy 1 to Policy n) interact with a shared environment. Each policy receives observations from the environment, takes actions, and is updated based on reward signals. The system emphasizes bidirectional communication between policies and the environment, with explicit feedback loops for policy updates.
### Components/Axes
1. **Environment**:
- Positioned at the top of the diagram.
- Sends observations (o₁, o₂, ..., oₙ) to policies via downward arrows.
- Receives actions (a₁, a₂, ..., aₙ) from policies via upward arrows.
2. **Policies**:
- Labeled sequentially as "Policy 1", "Policy 2", ..., "Policy n".
- Each policy has:
- A bidirectional arrow with the environment (action/observation exchange).
- A feedback loop labeled "Update with r₁", "Update with r₂", ..., "Update with rₙ" at the bottom.
3. **Feedback Loops**:
- Positioned below each policy.
- Arrows labeled r₁, r₂, ..., rₙ indicate reward-driven updates to respective policies.
### Detailed Analysis
- **Action-Observation Flow**:
- Each policy receives an observation (oᵢ) from the environment and sends an action (aᵢ) back.
- Observations and actions are indexed sequentially (1 to n), suggesting a parallel or distributed system.
- **Feedback Mechanism**:
- Rewards (r₁ to rₙ) are explicitly tied to individual policies, implying policy-specific updates.
- Feedback loops are isolated to each policy, preventing cross-policy interference during updates.
### Key Observations
1. **Modular Policy Design**: Each policy operates independently but shares the same environment, enabling parallel exploration/exploitation.
2. **Reward-Driven Updates**: Feedback loops are directly connected to policies, emphasizing reward-based learning (e.g., Q-learning, policy gradients).
3. **Scalability**: The use of "n" policies suggests the system can scale horizontally by adding more policies.
### Interpretation
This diagram represents a **multi-agent reinforcement learning (MARL)** framework where:
- Policies act as autonomous agents learning to optimize rewards through environment interaction.
- The absence of shared feedback between policies implies decentralized learning, avoiding coordination complexity.
- The explicit separation of observation/action channels and feedback loops highlights modularity, critical for real-world applications like robotics or autonomous systems.
The system prioritizes **individual policy optimization** while maintaining environmental consistency, a common trade-off in MARL to balance exploration and resource efficiency.