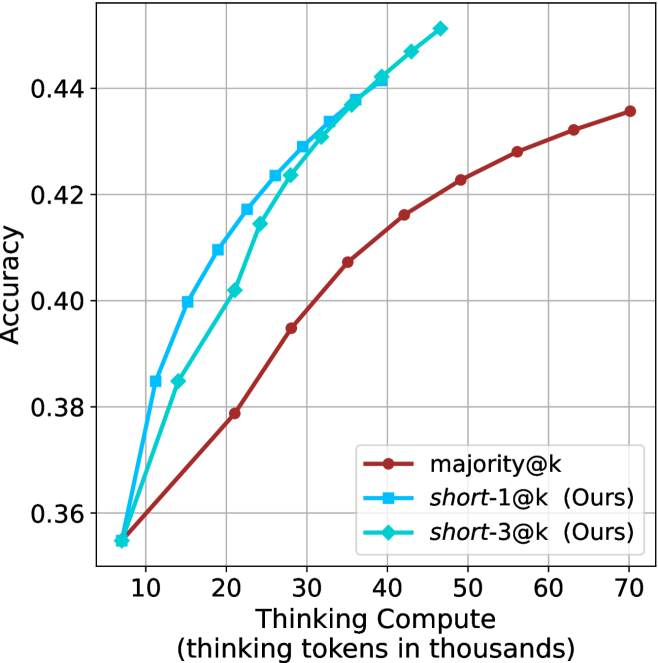
## Line Chart: Accuracy vs. Thinking Compute
### Overview
The chart compares the accuracy of three computational approaches ("majority@k", "short-1@k", and "short-3@k") across varying levels of thinking compute (measured in thousands of tokens). All three approaches show increasing accuracy with higher compute, but with distinct performance trajectories.
### Components/Axes
- **X-axis**: Thinking Compute (thinking tokens in thousands)
- Scale: 10 → 70 (increments of 10)
- Labels: Numerical values only (no units explicitly stated beyond axis title)
- **Y-axis**: Accuracy
- Scale: 0.36 → 0.44 (increments of 0.02)
- Labels: Decimal values (e.g., 0.36, 0.38, ..., 0.44)
- **Legend**:
- Position: Bottom-right corner
- Entries:
- Red: "majority@k"
- Blue: "short-1@k (Ours)"
- Green: "short-3@k (Ours)"
### Detailed Analysis
1. **majority@k (Red Line)**
- Starts at 0.36 accuracy at 10k tokens.
- Increases steadily to ~0.435 at 70k tokens.
- Slope: Linear growth (~0.001 accuracy per 1k tokens).
2. **short-1@k (Blue Line)**
- Starts at 0.36 accuracy at 10k tokens.
- Sharp upward trajectory until ~40k tokens (peaks at ~0.445).
- Plateaus after 50k tokens (~0.44 accuracy).
- Slope: Steep initial growth (~0.002 accuracy per 1k tokens), then flat.
3. **short-3@k (Green Line)**
- Starts at 0.36 accuracy at 10k tokens.
- Gradual upward trend, surpassing "majority@k" after ~30k tokens.
- Reaches ~0.44 accuracy at 70k tokens.
- Slope: Moderate growth (~0.0005 accuracy per 1k tokens).
### Key Observations
- **Performance Trends**:
- "short-1@k" achieves the highest accuracy early but plateaus.
- "short-3@k" shows sustained improvement, outperforming "majority@k" at higher compute levels.
- "majority@k" has the slowest growth but remains competitive at lower compute.
- **Notable Patterns**:
- Diminishing returns for "short-1@k" after 50k tokens.
- "short-3@k" demonstrates better scalability for large compute budgets.
### Interpretation
The data suggests that increasing thinking compute improves accuracy across all methods, but with varying efficiency:
- **short-1@k** is optimal for moderate compute budgets (up to 50k tokens) but offers no further gains beyond that.
- **short-3@k** provides better long-term scalability, maintaining improvement even at 70k tokens.
- **majority@k** serves as a baseline, with linear gains but lower ceiling accuracy.
The plateau in "short-1@k" implies potential architectural limitations at higher compute, while "short-3@k" may leverage more efficient resource allocation. These findings highlight trade-offs between model complexity and compute efficiency in accuracy optimization.