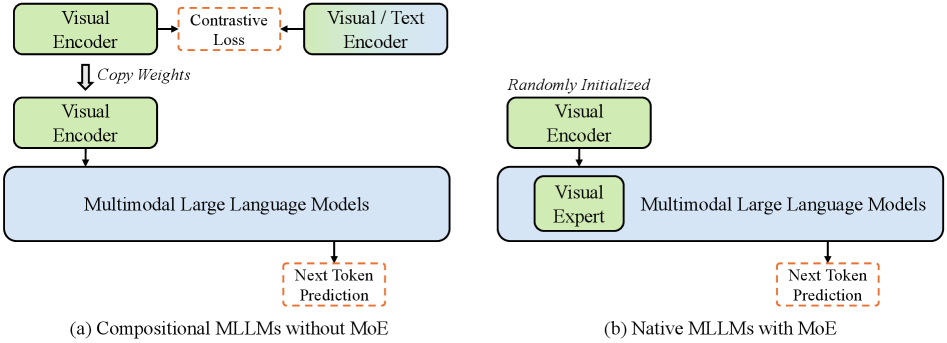
## Diagram: Compositional vs. Native Multimodal Large Language Models
### Overview
The image presents two diagrams illustrating different architectures for Multimodal Large Language Models (MLLMs). Diagram (a) depicts a "Compositional" approach without Mixture of Experts (MoE), while diagram (b) shows a "Native" approach with MoE. Both diagrams outline the flow of information and the interaction between visual encoders and the MLLM.
### Components/Axes
**Diagram (a): Compositional MLLMs without MoE**
* **Visual Encoder (Top-Left):** A green rounded rectangle labeled "Visual Encoder."
* **Contrastive Loss (Top-Center):** An orange dashed rounded rectangle labeled "Contrastive Loss."
* **Visual/Text Encoder (Top-Right):** A green rounded rectangle labeled "Visual / Text Encoder."
* **Copy Weights (Arrow):** A downward arrow labeled "Copy Weights" connecting the top "Visual Encoder" to a second "Visual Encoder" below.
* **Visual Encoder (Middle-Left):** A green rounded rectangle labeled "Visual Encoder."
* **Multimodal Large Language Models (Center):** A blue rounded rectangle labeled "Multimodal Large Language Models."
* **Next Token Prediction (Bottom-Center):** An orange dashed rounded rectangle labeled "Next Token Prediction."
* **Diagram Title:** "(a) Compositional MLLMs without MoE"
**Diagram (b): Native MLLMs with MoE**
* **Randomly Initialized (Text):** Text above the "Visual Encoder" stating "Randomly Initialized."
* **Visual Encoder (Top-Left):** A green rounded rectangle labeled "Visual Encoder."
* **Visual Expert (Middle-Left):** A green rounded rectangle labeled "Visual Expert" nested within the "Multimodal Large Language Models" block.
* **Multimodal Large Language Models (Center):** A blue rounded rectangle labeled "Multimodal Large Language Models."
* **Next Token Prediction (Bottom-Center):** An orange dashed rounded rectangle labeled "Next Token Prediction."
* **Diagram Title:** "(b) Native MLLMs with MoE"
### Detailed Analysis or Content Details
**Diagram (a):**
1. A "Visual Encoder" processes visual data.
2. The output is used to calculate "Contrastive Loss" in conjunction with a "Visual / Text Encoder."
3. The weights from the initial "Visual Encoder" are copied to a second "Visual Encoder."
4. This second "Visual Encoder" feeds into "Multimodal Large Language Models."
5. The MLLM produces a "Next Token Prediction."
**Diagram (b):**
1. A "Visual Encoder" is randomly initialized.
2. The output of the "Visual Encoder" is fed into "Multimodal Large Language Models."
3. A "Visual Expert" component is integrated within the MLLM.
4. The MLLM produces a "Next Token Prediction."
### Key Observations
* Diagram (a) emphasizes a compositional approach with weight sharing and contrastive learning.
* Diagram (b) highlights a native approach with a randomly initialized visual encoder and a "Visual Expert" module integrated into the MLLM.
* Both diagrams aim to achieve "Next Token Prediction" using multimodal information.
### Interpretation
The diagrams illustrate two distinct strategies for incorporating visual information into large language models. The "Compositional" approach (a) leverages pre-training and weight sharing to align visual and textual representations, potentially improving sample efficiency and generalization. The "Native" approach (b) integrates a "Visual Expert" directly into the MLLM, allowing the model to learn visual representations end-to-end. The choice between these architectures depends on factors such as the availability of pre-trained visual encoders, the desired level of integration between visual and textual modalities, and the computational resources available for training. The "Contrastive Loss" in (a) suggests a method to align the visual and textual embeddings, while the "Randomly Initialized" encoder in (b) suggests learning visual features from scratch within the MLLM framework.