# Technical Document Extraction: Multimodal Large Language Models (MLLMs)
## Diagram Analysis
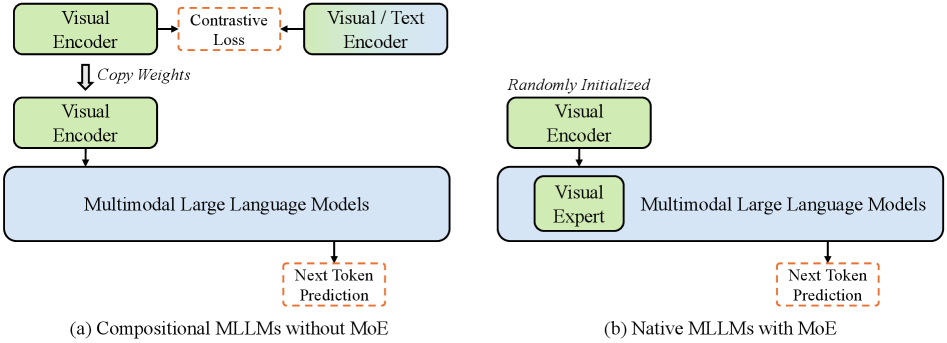
### Diagram (a): Compositional MLLMs without MoE
**Components and Flow:**
1. **Visual Encoder**
- Input: Visual data
- Output: Embeddings fed into "Contrastive Loss"
2. **Contrastive Loss**
- Function: Optimizes alignment between visual and textual representations
- Output: Processed embeddings
3. **Visual/Text Encoder**
- Input: Processed embeddings from "Contrastive Loss"
- Output: Multimodal representations
4. **Copy Weights**
- Mechanism: Transfers learned weights from the Visual Encoder to the Multimodal Large Language Models
5. **Multimodal Large Language Models**
- Input: Copied weights + textual context
- Output: **Next Token Prediction**
**Key Observations:**
- The architecture emphasizes **contrastive learning** to align visual and textual modalities.
- Weight copying ensures parameter efficiency by reusing the Visual Encoder's learned features.
---
### Diagram (b): Native MLLMs with MoE (Mixture of Experts)
**Components and Flow:**
1. **Visual Encoder**
- Initialization: **Randomly Initialized**
- Output: Embeddings fed into "Visual Expert"
2. **Visual Expert**
- Function: Specialized processing of visual embeddings
- Output: Enhanced visual features
3. **Multimodal Large Language Models**
- Input: Visual Expert output + textual context
- Output: **Next Token Prediction**
**Key Observations:**
- **MoE Integration**: Introduces a dedicated "Visual Expert" to handle modality-specific processing.
- **Random Initialization**: Visual Encoder starts without pre-trained weights, relying on end-to-end training.
---
## Cross-Diagram Comparison
| Feature | Diagram (a) | Diagram (b) |
|------------------------|--------------------------------------|--------------------------------------|
| **Architecture** | Compositional (modular components) | Native (end-to-end with MoE) |
| **Visual Encoder** | Pre-trained (weights copied) | Randomly initialized |
| **Modality Alignment** | Contrastive Loss | Visual Expert |
| **Output** | Next Token Prediction | Next Token Prediction |
**Critical Differences:**
- Diagram (a) uses **contrastive learning** for alignment, while Diagram (b) employs a **dedicated Visual Expert**.
- Diagram (b) avoids weight copying, favoring **random initialization** for the Visual Encoder.
---
## Notes
- **Language**: All textual elements are in English.
- **No Numerical Data**: The diagrams focus on architectural design rather than quantitative metrics.
- **Flow Direction**: Arrows indicate sequential processing from top to bottom in both diagrams.