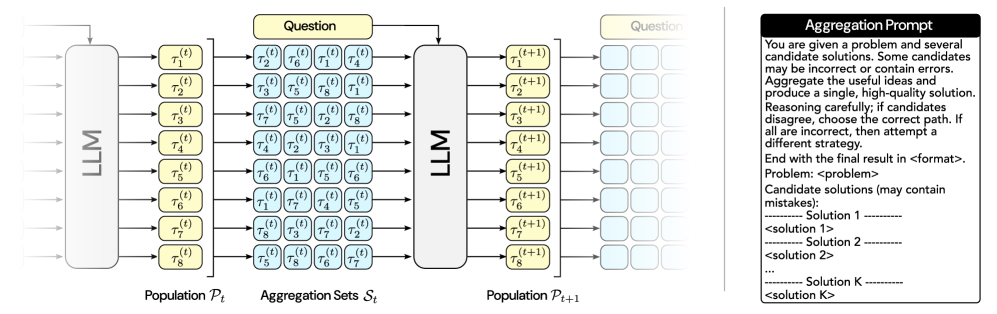
# Technical Document Extraction: LLM Iterative Aggregation Process
This document provides a detailed technical extraction of the provided image, which illustrates a computational workflow for iterative solution refinement using Large Language Models (LLMs).
## 1. Component Isolation
The image is divided into two primary sections:
* **Left Section (Main Diagram):** A flow diagram showing the transition from a population of solutions at time $t$ to a refined population at time $t+1$.
* **Right Section (Text Block):** A detailed transcription of the "Aggregation Prompt" used within the LLM nodes.
---
## 2. Main Diagram Analysis (Left Section)
The diagram depicts a sequential process of solution generation, grouping, and refinement.
### A. Population $\mathcal{P}_t$ (Initial State)
* **Input:** Multiple arrows enter a vertical rounded rectangle labeled **LLM**.
* **Output:** Eight distinct yellow nodes representing a population of solutions at time $t$.
* **Labels:** $\tau_1^{(t)}, \tau_2^{(t)}, \tau_3^{(t)}, \tau_4^{(t)}, \tau_5^{(t)}, \tau_6^{(t)}, \tau_7^{(t)}, \tau_8^{(t)}$.
* **Footer Label:** Population $\mathcal{P}_t$
### B. Aggregation Sets $\mathcal{S}_t$ (Intermediate State)
The solutions from $\mathcal{P}_t$ are shuffled and grouped into sets. Each row represents an aggregation set containing four elements.
* **Footer Label:** Aggregation Sets $\mathcal{S}_t$
* **Set Composition (by row):**
1. $\{\tau_2^{(t)}, \tau_6^{(t)}, \tau_1^{(t)}, \tau_4^{(t)}\}$
2. $\{\tau_3^{(t)}, \tau_5^{(t)}, \tau_8^{(t)}, \tau_1^{(t)}\}$
3. $\{\tau_7^{(t)}, \tau_5^{(t)}, \tau_2^{(t)}, \tau_8^{(t)}\}$
4. $\{\tau_4^{(t)}, \tau_2^{(t)}, \tau_3^{(t)}, \tau_1^{(t)}\}$
5. $\{\tau_6^{(t)}, \tau_1^{(t)}, \tau_5^{(t)}, \tau_6^{(t)}\}$
6. $\{\tau_1^{(t)}, \tau_7^{(t)}, \tau_4^{(t)}, \tau_5^{(t)}\}$
7. $\{\tau_8^{(t)}, \tau_3^{(t)}, \tau_7^{(t)}, \tau_2^{(t)}\}$
8. $\{\tau_5^{(t)}, \tau_8^{(t)}, \tau_6^{(t)}, \tau_7^{(t)}\}$
### C. Refinement Process
* **Inputs to LLM:** Each row (Aggregation Set) is fed into a second **LLM** node.
* **Global Input:** A yellow box labeled **Question** provides context to the LLM for the aggregation task.
* **Output:** Eight new yellow nodes representing the updated population.
* **Labels:** $\tau_1^{(t+1)}, \tau_2^{(t+1)}, \tau_3^{(t+1)}, \tau_4^{(t+1)}, \tau_5^{(t+1)}, \tau_6^{(t+1)}, \tau_7^{(t+1)}, \tau_8^{(t+1)}$.
* **Footer Label:** Population $\mathcal{P}_{t+1}$
---
## 3. Aggregation Prompt Transcription (Right Section)
The following text is contained within the black-header box on the right side of the image.
| Field | Content |
| :--- | :--- |
| **Header** | **Aggregation Prompt** |
| **Instruction Text** | You are given a problem and several candidate solutions. Some candidates may be incorrect or contain errors. Aggregate the useful ideas and produce a single, high-quality solution. Reasoning carefully; if candidates disagree, choose the correct path. If all are incorrect, then attempt a different strategy. End with the final result in \<format\>. |
| **Data Fields** | **Problem:** \<problem\> <br> **Candidate solutions (may contain mistakes):** |
| **Template Structure** | ---------- Solution 1 ---------- <br> \<solution 1\> <br> ---------- Solution 2 ---------- <br> \<solution 2\> <br> ... <br> ---------- Solution K ---------- <br> \<solution K\> |
---
## 4. Process Flow Summary
1. **Generation:** An LLM generates an initial population of solutions ($\mathcal{P}_t$).
2. **Permutation/Grouping:** These solutions are organized into Aggregation Sets ($\mathcal{S}_t$). Each set contains a subset of the population, often repeating or mixing indices.
3. **Contextual Aggregation:** The LLM receives the original **Question** and a specific **Aggregation Set**.
4. **Refinement:** Using the "Aggregation Prompt" logic, the LLM synthesizes the candidate solutions into a new, improved solution.
5. **Iteration:** This results in a new population ($\mathcal{P}_{t+1}$), and the diagram suggests the process repeats (indicated by the faded blue boxes on the far right).