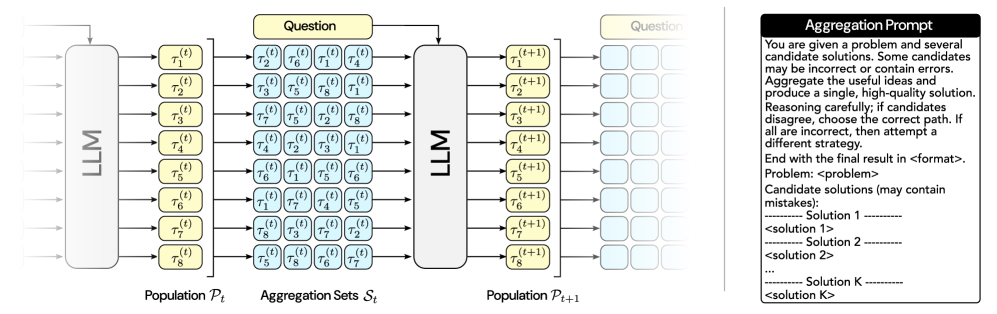
# Technical Document Extraction: Image Analysis
## Diagram Description
The image depicts a **flowchart** representing a multi-stage language model (LLM) processing pipeline. Below is a detailed breakdown of components, labels, and flow:
### Key Components
1. **Left Block**: Labeled `LLM` (Language Model)
- Represents the initial processing unit.
- Outputs a population `P_t` (temporal subscript indicates time step `t`).
2. **Central Aggregation Stage**:
- **Input**: Population `P_t` from the left LLM.
- **Process**:
- Generates **Aggregation Sets** `S_t` (temporal subscript `t`).
- Each set contains 8 candidate solutions (e.g., `τ₁^(t)`, `τ₂^(t)`, ..., `τ₈^(t)`).
- **Output**:
- A **Question** node (central yellow box).
- The Question node feeds back into the LLM for iterative refinement.
3. **Right Block**: Labeled `LLM` (Language Model)
- Receives the Question node as input.
- Outputs a refined population `P_{t+1}` (temporal subscript `t+1`).
### Flowchart Arrows
- **Left to Center**:
- `P_t` → `Aggregation Sets S_t` (8 candidate solutions per set).
- **Center to Right**:
- `Question` → `P_{t+1}` (refined population).
### Labels and Annotations
- **Axis Titles**:
- `Population P_t` (left), `Aggregation Sets S_t` (center), `Population P_{t+1}` (right).
- **Legend**:
- No explicit legend present. Colors differentiate components:
- **Yellow**: Question node.
- **Blue**: Aggregation sets (`S_t`).
- **Gray**: LLM blocks.
- **White**: Population nodes (`P_t`, `P_{t+1}`).
## Text Box Content: Aggregation Prompt
The right-side text box contains a **prompt** for aggregating candidate solutions. Transcribed verbatim: