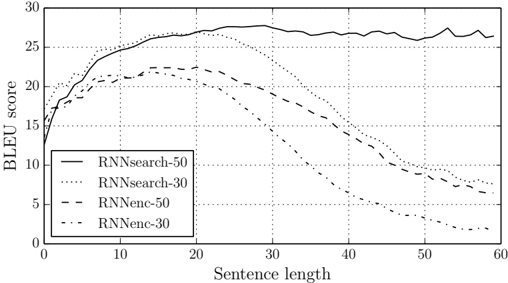
## Line Chart: BLEU Score vs. Sentence Length
### Overview
This image presents a line chart illustrating the relationship between sentence length and BLEU score for four different model configurations. The chart compares the performance of RNN search and RNN encoder-decoder models with varying hidden state sizes (30 and 50).
### Components/Axes
* **X-axis:** Sentence length, ranging from 0 to 60. Marked at intervals of 10.
* **Y-axis:** BLEU score, ranging from 0 to 30. Marked at intervals of 5.
* **Legend:** Located in the top-left corner, containing the following labels and corresponding line styles/colors:
* RNNsearch-50 (Solid black line)
* RNNsearch-30 (Dotted black line)
* RNNenc-50 (Dashed black line)
* RNNenc-30 (Dash-dotted black line)
### Detailed Analysis
The chart displays four distinct lines representing the BLEU scores for each model configuration as sentence length increases.
* **RNNsearch-50 (Solid Black):** This line exhibits an upward trend from a sentence length of 0 to approximately 20, reaching a peak BLEU score of around 28. It then plateaus, fluctuating between 26 and 29 for sentence lengths between 20 and 60.
* At sentence length 0: BLEU score ≈ 14
* At sentence length 10: BLEU score ≈ 24
* At sentence length 20: BLEU score ≈ 28
* At sentence length 30: BLEU score ≈ 28
* At sentence length 40: BLEU score ≈ 27
* At sentence length 50: BLEU score ≈ 26
* At sentence length 60: BLEU score ≈ 25
* **RNNsearch-30 (Dotted Black):** This line shows a similar upward trend initially, but reaches a lower peak BLEU score of approximately 25 at a sentence length of around 20. It then declines steadily from 20 to 60, falling to a BLEU score of around 8 at a sentence length of 60.
* At sentence length 0: BLEU score ≈ 14
* At sentence length 10: BLEU score ≈ 21
* At sentence length 20: BLEU score ≈ 25
* At sentence length 30: BLEU score ≈ 21
* At sentence length 40: BLEU score ≈ 14
* At sentence length 50: BLEU score ≈ 10
* At sentence length 60: BLEU score ≈ 8
* **RNNenc-50 (Dashed Black):** This line starts with a rapid increase, reaching a BLEU score of approximately 22 at a sentence length of 10. It continues to rise, but at a slower rate, reaching a peak of around 26 at a sentence length of 30. After 30, the BLEU score declines to approximately 18 at a sentence length of 60.
* At sentence length 0: BLEU score ≈ 15
* At sentence length 10: BLEU score ≈ 22
* At sentence length 20: BLEU score ≈ 24
* At sentence length 30: BLEU score ≈ 26
* At sentence length 40: BLEU score ≈ 22
* At sentence length 50: BLEU score ≈ 16
* At sentence length 60: BLEU score ≈ 18
* **RNNenc-30 (Dash-dotted Black):** This line exhibits a similar pattern to RNNenc-50, but with lower BLEU scores overall. It starts at around 15, peaks at approximately 20 at a sentence length of 20, and then declines to around 6 at a sentence length of 60.
* At sentence length 0: BLEU score ≈ 15
* At sentence length 10: BLEU score ≈ 19
* At sentence length 20: BLEU score ≈ 20
* At sentence length 30: BLEU score ≈ 16
* At sentence length 40: BLEU score ≈ 10
* At sentence length 50: BLEU score ≈ 7
* At sentence length 60: BLEU score ≈ 6
### Key Observations
* The RNNsearch-50 model consistently outperforms the other models, particularly for longer sentence lengths.
* Increasing the hidden state size from 30 to 50 generally improves BLEU scores, especially for the RNNsearch model.
* All models exhibit a decline in BLEU score for very long sentences (beyond 30-40), suggesting a limitation in their ability to accurately generate or evaluate longer sequences.
* The RNNsearch models show a more stable performance for longer sentences compared to the RNNenc models.
### Interpretation
The data suggests that the RNNsearch-50 model is the most effective configuration for generating or evaluating sentences, particularly as sentence length increases. The higher BLEU scores indicate better alignment between the generated/evaluated sentences and reference sentences. The decline in BLEU scores for longer sentences across all models could be attributed to the vanishing gradient problem or the difficulty of capturing long-range dependencies in sequential data. The difference in performance between the 30 and 50 hidden state sizes highlights the importance of model capacity in capturing complex relationships within the data. The contrast between the search and encoder-decoder approaches suggests that the search strategy is more robust to sentence length variations. This chart provides valuable insights into the trade-offs between model complexity, sentence length, and translation quality.