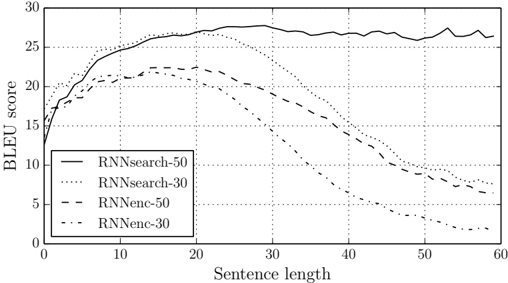
## Line Graph: BLEU Score vs. Sentence Length
### Overview
The graph illustrates the relationship between sentence length (x-axis) and BLEU score (y-axis) for four neural network models: RNNsearch-50, RNNsearch-30, RNNenc-50, and RNNenc-30. The BLEU score measures translation quality, while sentence length represents input/output sequence lengths.
### Components/Axes
- **Y-axis (BLEU score)**: Ranges from 0 to 30 in increments of 5.
- **X-axis (Sentence length)**: Ranges from 0 to 60 in increments of 10.
- **Legend**: Located in the bottom-left corner, associating line styles/colors with models:
- Solid black: RNNsearch-50
- Dotted black: RNNsearch-30
- Dashed black: RNNenc-50
- Dash-dot black: RNNenc-30
### Detailed Analysis
1. **RNNsearch-50 (solid black)**:
- Starts at 0 BLEU score for 0-length sentences.
- Rises sharply to ~28 BLEU at 20-length sentences.
- Plateaus between 27–28 BLEU for sentences 20–60 lengths.
- Minor fluctuations observed near 50–60 lengths.
2. **RNNsearch-30 (dotted black)**:
- Begins at 0 BLEU score.
- Peaks at ~22 BLEU at 15-length sentences.
- Declines steadily to ~10 BLEU at 50-length sentences.
- Slight recovery to ~12 BLEU at 60 lengths.
3. **RNNenc-50 (dashed black)**:
- Starts at 0 BLEU score.
- Peaks at ~20 BLEU at 15-length sentences.
- Declines to ~10 BLEU at 50-length sentences.
- Slight uptick to ~12 BLEU at 60 lengths.
4. **RNNenc-30 (dash-dot black)**:
- Begins at 0 BLEU score.
- Peaks at ~15 BLEU at 10-length sentences.
- Declines to ~5 BLEU at 50-length sentences.
- Minimal recovery to ~7 BLEU at 60 lengths.
### Key Observations
- **Model Performance**: RNNsearch models consistently outperform RNNenc models across all sentence lengths.
- **Sentence Length Impact**:
- Optimal performance occurs at 15–20-length sentences for all models.
- Longer sentences (>30) show diminishing returns or performance drops.
- **Parameter Size**: 50-parameter models (RNNsearch-50, RNNenc-50) achieve higher BLEU scores than 30-parameter counterparts.
- **RNNenc Decline**: RNNenc models exhibit sharper declines in BLEU scores for longer sentences compared to RNNsearch.
### Interpretation
The data suggests that RNNsearch architectures are more robust for translation tasks, maintaining higher BLEU scores even as sentence length increases. The plateau in RNNsearch-50 indicates diminishing gains beyond 20-length sentences, while RNNenc models struggle with longer sequences, possibly due to architectural limitations in handling context. The parameter size (50 vs. 30) directly correlates with performance, emphasizing the importance of model capacity. The decline in longer sentences may reflect overfitting or insufficient training data for extended contexts. RNNenc’s lower scores highlight potential inefficiencies in its design for sequence-to-sequence tasks.