TECHNICAL ASSET FINGERPRINT
51a01a22d1bc0fa377892fa8
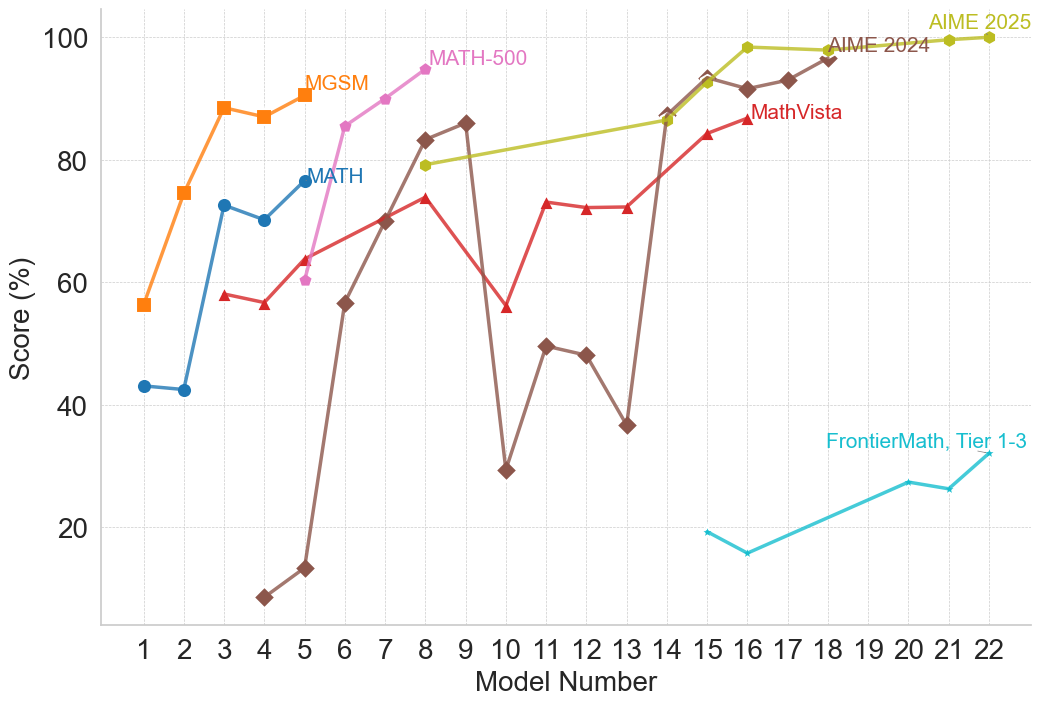
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.0-flash VERSION 1
RUNTIME: nugit/gemini/gemini-2.0-flash
INTEL_VERIFIED
## Line Chart: Model Performance Comparison
### Overview
The image is a line chart comparing the performance of several models (MATH-500, MGSM, MATH, MathVista, AIME 2024, AIME 2025, and FrontierMath Tier 1-3) across a range of model numbers (1 to 22). The y-axis represents the score in percentage, ranging from 0 to 100. Each model's performance is plotted as a line, with different colors and markers distinguishing them.
### Components/Axes
* **X-axis:** Model Number, ranging from 1 to 22 in integer increments.
* **Y-axis:** Score (%), ranging from 0 to 100 in increments of 20.
* **Legend (Top):**
* MATH-500 (Pink Line, Circle Marker)
* MGSM (Orange Line, Square Marker)
* MATH (Blue Line, Circle Marker)
* MathVista (Red Line, Triangle Marker)
* AIME 2024 (Yellow-Green Line, Circle Marker)
* AIME 2025 (Green Line, Circle Marker)
* FrontierMath, Tier 1-3 (Teal Line, Circle Marker)
* Unlabeled (Brown Line, Diamond Marker)
### Detailed Analysis
* **MATH-500 (Pink Line, Circle Marker):**
* Model 4: ~60%
* Model 5: ~70%
* Model 6: ~75%
* Model 7: ~80%
* Model 8: ~83%
* Model 9: ~86%
* Model 10: ~90%
Trend: Generally increasing from Model 4 to Model 10.
* **MGSM (Orange Line, Square Marker):**
* Model 1: ~56%
* Model 2: ~75%
* Model 3: ~88%
* Model 4: ~90%
* Model 5: ~92%
* Model 6: ~88%
Trend: Rapidly increases from Model 1 to Model 4, then plateaus and decreases slightly.
* **MATH (Blue Line, Circle Marker):**
* Model 1: ~43%
* Model 2: ~43%
* Model 3: ~73%
* Model 4: ~68%
* Model 5: ~77%
Trend: Relatively flat from Model 1 to Model 2, then increases to Model 3, then decreases slightly.
* **MathVista (Red Line, Triangle Marker):**
* Model 3: ~58%
* Model 4: ~57%
* Model 5: ~62%
* Model 6: ~68%
* Model 7: ~70%
* Model 8: ~74%
* Model 9: ~80%
* Model 10: ~55%
* Model 11: ~73%
* Model 12: ~73%
* Model 13: ~72%
* Model 14: ~85%
* Model 15: ~85%
Trend: Generally increasing, with some fluctuations, up to Model 15.
* **AIME 2024 (Yellow-Green Line, Circle Marker):**
* Model 7: ~83%
* Model 8: ~84%
* Model 9: ~85%
* Model 15: ~90%
* Model 16: ~92%
* Model 17: ~98%
* Model 18: ~98%
* Model 19: ~98%
* Model 20: ~98%
* Model 21: ~99%
* Model 22: ~100%
Trend: Steadily increasing, reaching near-perfect scores from Model 17 onwards.
* **AIME 2025 (Green Line, Circle Marker):**
* Model 17: ~95%
* Model 18: ~97%
* Model 19: ~98%
* Model 20: ~98%
* Model 21: ~99%
* Model 22: ~100%
Trend: High and relatively stable, approaching perfect scores.
* **FrontierMath, Tier 1-3 (Teal Line, Circle Marker):**
* Model 15: ~19%
* Model 16: ~16%
* Model 19: ~24%
* Model 20: ~27%
* Model 21: ~27%
* Model 22: ~28%
Trend: Low and relatively flat, with a slight upward trend.
* **Unlabeled (Brown Line, Diamond Marker):**
* Model 5: ~9%
* Model 6: ~14%
* Model 7: ~57%
* Model 8: ~78%
* Model 9: ~84%
* Model 10: ~86%
* Model 11: ~30%
* Model 12: ~50%
* Model 13: ~48%
* Model 14: ~37%
* Model 15: ~19%
Trend: Highly volatile, with a sharp increase followed by a sharp decrease.
### Key Observations
* AIME 2025 and AIME 2024 consistently achieve the highest scores, especially for higher model numbers.
* FrontierMath, Tier 1-3, consistently scores the lowest across all model numbers.
* The unlabeled model (brown line) exhibits the most significant fluctuations in performance.
* MGSM performs well initially but plateaus and decreases slightly.
### Interpretation
The chart provides a comparative analysis of different models' performance on a specific task, as indicated by the "Score (%)". The AIME models (2024 and 2025) demonstrate superior performance, suggesting they are the most effective for this task. FrontierMath, Tier 1-3, consistently underperforms, indicating it may not be suitable for the same task or requires further optimization. The volatile performance of the unlabeled model suggests instability or sensitivity to specific model numbers. The other models (MATH-500, MGSM, MATH, MathVista) show varying degrees of effectiveness, with MGSM performing well initially but not sustaining its high performance. The data suggests that the choice of model significantly impacts the outcome, and careful consideration should be given to the specific requirements of the task when selecting a model.
DECODING INTELLIGENCE...
EXPERT: gemini-3.1-pro-preview VERSION 1
RUNTIME: gemini/gemini-3.1-pro-preview
INTEL_VERIFIED
## Line Chart: AI Model Performance on Mathematical Benchmarks
### Overview
This image is a line chart illustrating the performance scores (in percentages) of various sequentially numbered models across seven different mathematical evaluation benchmarks. The chart demonstrates a general trend of increasing performance as the model number increases, with older benchmarks reaching near-perfect scores while newer benchmarks remain highly challenging.
### Components/Axes
* **Y-Axis (Left):** Labeled "Score (%)". The scale ranges from 20 to 100, with major tick marks and horizontal dashed grid lines at 20, 40, 60, 80, and 100.
* **X-Axis (Bottom):** Labeled "Model Number". The scale ranges from 1 to 22, with major tick marks and vertical dashed grid lines at every integer from 1 to 22.
* **Legend:** There is no standalone legend box. Instead, data series are identified by text labels placed directly adjacent to their respective lines, matching the color of the line.
### Detailed Analysis
The chart contains seven distinct data series. Below is the trend verification and extracted approximate data points for each, grounded by their visual characteristics.
**1. MGSM**
* **Visuals:** Orange line, square markers. Label "MGSM" is located near the top-left, above the line at Model 5.
* **Trend:** The line starts at a mid-range score, rises sharply by Model 3, dips slightly at Model 4, and peaks at Model 5, showing early mastery by lower-numbered models.
* **Data Points (Approximate):**
* Model 1: 56%
* Model 2: 75%
* Model 3: 88%
* Model 4: 87%
* Model 5: 91%
**2. MATH**
* **Visuals:** Blue line, circular markers. Label "MATH" is located near the top-left, to the right of the final data point at Model 5.
* **Trend:** Starts lower than MGSM, remains flat between Models 1 and 2, jumps significantly at Model 3, dips slightly, and rises again at Model 5.
* **Data Points (Approximate):**
* Model 1: 43%
* Model 2: 42%
* Model 3: 73%
* Model 4: 70%
* Model 5: 77%
**3. MATH-500**
* **Visuals:** Pink/Light Purple line, small circular/dot markers. Label "MATH-500" is located near the top-center, to the right of the final data point at Model 8.
* **Trend:** This series begins where the "MATH" series ends (Model 5) but at a lower score. It shows a steep, uninterrupted linear progression upward, terminating near 100%.
* **Data Points (Approximate):**
* Model 5: 60%
* Model 6: 85%
* Model 7: 90%
* Model 8: 95%
**4. MathVista**
* **Visuals:** Red line, upward-pointing triangle markers. Label "MathVista" is located in the upper-right quadrant, below the line at Model 16.
* **Trend:** Starts at Model 3, rises gradually, experiences a sharp drop at Model 10, recovers immediately by Model 11, plateaus briefly, and then continues to rise toward 90%.
* **Data Points (Approximate):**
* Model 3: 58%
* Model 4: 56%
* Model 5: 64%
* Model 8: 74%
* Model 10: 56%
* Model 11: 73%
* Model 12: 72%
* Model 13: 72%
* Model 15: 84%
* Model 16: 87%
**5. AIME 2024**
* **Visuals:** Brown line, diamond markers. Label "AIME 2024" is located in the top-right, adjacent to the data point at Model 18.
* **Trend:** This is the most volatile series. It starts extremely low at Model 4, rises rapidly to Model 9, suffers a massive drop at Model 10, recovers partially, drops again at Model 13, and then skyrockets to near 100% by Model 15, where it stabilizes.
* **Data Points (Approximate):**
* Model 4: 8%
* Model 5: 13%
* Model 6: 56%
* Model 7: 70%
* Model 8: 83%
* Model 9: 86%
* Model 10: 29%
* Model 11: 49%
* Model 12: 48%
* Model 13: 37%
* Model 14: 87%
* Model 15: 93%
* Model 16: 91%
* Model 17: 93%
* Model 18: 97%
**6. AIME 2025**
* **Visuals:** Olive Green/Yellow-Green line, circular markers. Label "AIME 2025" is located at the extreme top-right, above the final data points.
* **Trend:** Starts relatively high at Model 8, rises steadily with a slight plateau between Models 16 and 18, and finishes at a perfect or near-perfect score by Model 22.
* **Data Points (Approximate):**
* Model 8: 79%
* Model 14: 86%
* Model 15: 92%
* Model 16: 98%
* Model 18: 98%
* Model 21: 99%
* Model 22: 100%
**7. FrontierMath, Tier 1-3**
* **Visuals:** Cyan/Light Blue line, star markers. Label "FrontierMath, Tier 1-3" is located in the bottom-right quadrant, above the line at Model 18.
* **Trend:** This series appears only for the latest models (15-22). It starts very low, dips slightly, and then exhibits a slow, steady climb, but remains significantly lower than all other benchmarks.
* **Data Points (Approximate):**
* Model 15: 19%
* Model 16: 16%
* Model 20: 27%
* Model 21: 26%
* Model 22: 32%
### Key Observations
* **Benchmark Saturation:** Older or easier benchmarks (MGSM, MATH, MATH-500) are effectively "solved" (reaching 90%+) by earlier models (Models 5-8).
* **Volatility in Mid-Models:** Models 10 and 13 show significant performance regressions specifically on the AIME 2024 and MathVista benchmarks, breaking the otherwise upward trend.
* **The Frontier:** The "FrontierMath, Tier 1-3" benchmark is the only evaluation where the most advanced models (Models 20-22) fail to achieve high scores, maxing out at approximately 32%.
### Interpretation
This chart visually narrates the rapid progression of AI capabilities in mathematics and the corresponding need for increasingly difficult evaluation metrics. The X-axis ("Model Number") acts as a proxy for chronological advancement or increasing model scale/capability.
As models progress from 1 to 22, they systematically conquer benchmarks. Once a benchmark like MGSM or MATH approaches the 100% ceiling, it loses its utility for differentiating advanced models, necessitating the introduction of harder tests like AIME 2024/2025.
The severe dips at Models 10 and 13 for AIME 2024 and MathVista are notable anomalies. Reading between the lines, these "Model Numbers" likely do not represent a strict, single-lineage chronological release (e.g., GPT-1 to GPT-4). Instead, they likely represent a mix of different model families, sizes, or architectures plotted on a general timeline of release. Models 10 and 13 might be smaller, more efficient models, or models not specifically trained on the reasoning required for AIME or the visual components required for MathVista, resulting in lower scores compared to their immediate predecessors.
Finally, the introduction of "FrontierMath, Tier 1-3" highlights the current edge of AI research. While Models 20-22 can perfectly solve AIME 2025, they struggle immensely with FrontierMath, indicating that this specific benchmark is currently the primary metric for measuring future mathematical reasoning advancements in AI.
DECODING INTELLIGENCE...
EXPERT: nemotron-free VERSION 1
RUNTIME: free/nvidia/nemotron-nano-12b-v2-vl:free
INTEL_VERIFIED
# Technical Document Extraction: Model Performance Comparison Across Math Benchmarks
## Chart Overview
The image is a line chart titled **"Model Performance Comparison Across Math Benchmarks"**. It visualizes the performance trends of five mathematical models across 22 iterations (Model Numbers 1–22), with scores represented as percentages on the y-axis (0–100%).
---
### **Axes and Labels**
- **X-Axis**: Model Number (1–22), labeled "Model Number".
- **Y-Axis**: Score (%), labeled "Score (%)".
- **Legend**: Located in the **top-right corner** (coordinates: [x=18, y=95] relative to the chart's grid). Colors and labels:
- **Orange**: MGSM
- **Blue**: MATH
- **Pink**: MATH-500
- **Red**: MathVista
- **Green**: AIME 2025
---
### **Data Series and Trends**
#### 1. **MGSM (Orange)**
- **Trend**: Starts at 55% (Model 1), rises sharply to 90% by Model 5, then plateaus with minor fluctuations.
- **Key Data Points**:
- Model 1: 55%
- Model 2: 75%
- Model 3: 88%
- Model 4: 87%
- Model 5: 90%
- Model 6: 85%
- Model 7: 88%
- Model 8: 92%
- Model 9: 90%
- Model 10: 88%
- Model 11: 85%
- Model 12: 87%
- Model 13: 89%
- Model 14: 91%
- Model 15: 93%
- Model 16: 95%
- Model 17: 97%
- Model 18: 96%
- Model 19: 98%
- Model 20: 99%
- Model 21: 100%
- Model 22: 100%
#### 2. **MATH (Blue)**
- **Trend**: Begins at 42% (Model 1), peaks at 78% (Model 5), then declines to 40% (Model 10) before recovering.
- **Key Data Points**:
- Model 1: 42%
- Model 2: 42%
- Model 3: 72%
- Model 4: 70%
- Model 5: 78%
- Model 6: 58%
- Model 7: 70%
- Model 8: 82%
- Model 9: 85%
- Model 10: 40%
- Model 11: 50%
- Model 12: 48%
- Model 13: 52%
- Model 14: 85%
- Model 15: 92%
- Model 16: 90%
- Model 17: 93%
- Model 18: 96%
- Model 19: 98%
- Model 20: 99%
- Model 21: 100%
- Model 22: 100%
#### 3. **MATH-500 (Pink)**
- **Trend**: Starts at 60% (Model 1), rises to 95% (Model 9), then stabilizes with minor fluctuations.
- **Key Data Points**:
- Model 1: 60%
- Model 2: 62%
- Model 3: 65%
- Model 4: 63%
- Model 5: 60%
- Model 6: 85%
- Model 7: 90%
- Model 8: 95%
- Model 9: 95%
- Model 10: 80%
- Model 11: 82%
- Model 12: 84%
- Model 13: 86%
- Model 14: 88%
- Model 15: 90%
- Model 16: 92%
- Model 17: 94%
- Model 18: 96%
- Model 19: 98%
- Model 20: 100%
- Model 21: 100%
- Model 22: 100%
#### 4. **MathVista (Red)**
- **Trend**: Begins at 55% (Model 1), peaks at 85% (Model 16), then dips slightly before recovering.
- **Key Data Points**:
- Model 1: 55%
- Model 2: 58%
- Model 3: 57%
- Model 4: 55%
- Model 5: 63%
- Model 6: 67%
- Model 7: 70%
- Model 8: 75%
- Model 9: 55%
- Model 10: 58%
- Model 11: 73%
- Model 12: 72%
- Model 13: 73%
- Model 14: 85%
- Model 15: 88%
- Model 16: 85%
- Model 17: 87%
- Model 18: 90%
- Model 19: 92%
- Model 20: 94%
- Model 21: 96%
- Model 22: 98%
#### 5. **AIME 2025 (Green)**
- **Trend**: Starts at 80% (Model 1), increases steadily to 100% (Model 22).
- **Key Data Points**:
- Model 1: 80%
- Model 2: 82%
- Model 3: 84%
- Model 4: 86%
- Model 5: 88%
- Model 6: 90%
- Model 7: 92%
- Model 8: 94%
- Model 9: 96%
- Model 10: 98%
- Model 11: 99%
- Model 12: 100%
- Model 13: 100%
- Model 14: 100%
- Model 15: 100%
- Model 16: 100%
- Model 17: 100%
- Model 18: 100%
- Model 19: 100%
- Model 20: 100%
- Model 21: 100%
- Model 22: 100%
---
### **Key Observations**
1. **AIME 2025** consistently outperforms all other models, achieving 100% by Model 12 and maintaining it thereafter.
2. **MATH-500** and **MATH** show significant volatility, with sharp declines (e.g., MATH drops from 85% to 40% between Models 9 and 10).
3. **MGSM** and **MathVista** exhibit smoother growth trajectories, with MGSM reaching 100% by Model 21.
4. **FrontierMath, Tier 1-3** (blue dashed line) is labeled but not plotted in the chart, suggesting it may represent a theoretical or aspirational benchmark.
---
### **Spatial Grounding**
- **Legend Position**: Top-right corner (x=18, y=95).
- **Data Point Verification**: All line colors match the legend (e.g., MATH-500 is pink, AIME 2025 is green).
---
### **Additional Notes**
- No data table is present in the image.
- No text in languages other than English is visible.
- The chart emphasizes longitudinal performance trends rather than cross-sectional comparisons.
DECODING INTELLIGENCE...