## Scatter Plot & Line Graph: Model Performance vs. Acceleration and Latency
### Overview
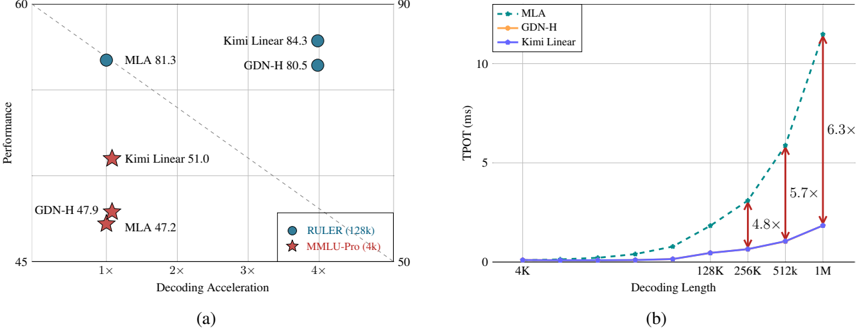
The image contains two distinct charts, labeled (a) and (b), comparing the performance and latency characteristics of three computational methods: MLA, GDN-H, and Kimi Linear. Chart (a) is a scatter plot evaluating performance against decoding acceleration on two different benchmarks. Chart (b) is a line graph showing how time per output token (TPOT) scales with increasing decoding length for the same three methods.
### Components/Axes
**Chart (a) - Scatter Plot:**
* **X-Axis:** "Decoding Acceleration". Scale markers at 1x, 2x, 3x, 4x.
* **Y-Axis:** "Performance". Scale ranges from 45 to 90.
* **Legend (Bottom-Right):**
* Blue Circle: "RULER (128k)"
* Red Star: "MMLU-Pro (3k)"
* **Data Points (with labels):**
* Blue Circles (RULER): "MLA 81.3", "Kimi Linear 84.3", "GDN-H 80.5"
* Red Stars (MMLU-Pro): "GDN-H 47.9", "MLA 47.2", "Kimi Linear 51.0"
**Chart (b) - Line Graph:**
* **X-Axis:** "Decoding Length". Logarithmic scale with markers at 4K, 128K, 256K, 512K, 1M.
* **Y-Axis:** "TPOT (ms)". Scale ranges from 0 to 10.
* **Legend (Top-Left):**
* Green Dashed Line: "MLA"
* Orange Solid Line: "GDN-H"
* Blue Solid Line: "Kimi Linear"
* **Annotations:** Red double-headed arrows with text indicating relative speedup factors: "4.8x" (between GDN-H and Kimi Linear at ~256K), "5.7x" (at ~512K), and "6.3x" (at 1M).
### Detailed Analysis
**Chart (a) Analysis:**
* **Trend Verification:** The plot shows a general positive correlation between Decoding Acceleration and Performance for both benchmarks. Methods positioned further to the right (higher acceleration) also tend to be higher up (better performance).
* **Data Points (Approximate):**
* **RULER (128k) - Blue Circles:**
* MLA: Performance ≈ 81.3, Acceleration ≈ 1.0x.
* GDN-H: Performance ≈ 80.5, Acceleration ≈ 3.8x.
* Kimi Linear: Performance ≈ 84.3, Acceleration ≈ 3.8x.
* **MMLU-Pro (3k) - Red Stars:**
* MLA: Performance ≈ 47.2, Acceleration ≈ 1.0x.
* GDN-H: Performance ≈ 47.9, Acceleration ≈ 1.0x.
* Kimi Linear: Performance ≈ 51.0, Acceleration ≈ 1.0x.
* **Spatial Grounding:** The legend is placed in the bottom-right corner of the plot area. The data points for GDN-H and Kimi Linear on the RULER benchmark are clustered closely together at the high-acceleration, high-performance end of the chart (top-right quadrant).
**Chart (b) Analysis:**
* **Trend Verification:** All three lines show an upward trend, indicating TPOT increases with decoding length. The MLA (green dashed) line has the steepest slope, followed by GDN-H (orange), with Kimi Linear (blue) having the shallowest slope.
* **Data Points & Relationships (Approximate from visual inspection):**
* At 4K length: All methods have near-zero TPOT.
* At 128K length: MLA TPOT ≈ 1.5 ms, GDN-H ≈ 0.5 ms, Kimi Linear ≈ 0.3 ms.
* At 256K length: MLA TPOT ≈ 3.0 ms, GDN-H ≈ 1.0 ms, Kimi Linear ≈ 0.6 ms. The annotation indicates Kimi Linear is **4.8x** faster than GDN-H here.
* At 512K length: MLA TPOT ≈ 6.0 ms, GDN-H ≈ 2.0 ms, Kimi Linear ≈ 1.0 ms. The annotation indicates Kimi Linear is **5.7x** faster than GDN-H here.
* At 1M length: MLA TPOT ≈ 11.0 ms (extrapolated beyond axis), GDN-H ≈ 3.5 ms, Kimi Linear ≈ 1.8 ms. The annotation indicates Kimi Linear is **6.3x** faster than GDN-H here.
* **Spatial Grounding:** The legend is placed in the top-left corner of the plot area. The red annotation arrows are positioned vertically between the GDN-H (orange) and Kimi Linear (blue) lines at the 256K, 512K, and 1M length markers.
### Key Observations
1. **Performance Leadership:** Kimi Linear achieves the highest performance score on both the RULER (84.3) and MMLU-Pro (51.0) benchmarks among the compared methods.
2. **Acceleration Disparity:** On the RULER benchmark, GDN-H and Kimi Linear offer a significant decoding acceleration (~3.8x) over MLA (~1.0x), while maintaining or exceeding MLA's performance. On the MMLU-Pro benchmark, all methods show similar, low acceleration (~1.0x).
3. **Latency Scaling:** The latency (TPOT) of MLA degrades much more rapidly with sequence length compared to GDN-H and Kimi Linear. Kimi Linear demonstrates the most favorable scaling, maintaining the lowest TPOT across all measured lengths.
4. **Relative Speedup:** The performance gap in latency between Kimi Linear and GDN-H widens as sequence length increases, from 4.8x at 256K to 6.3x at 1M tokens.
### Interpretation
The data presents a compelling case for the Kimi Linear method. It demonstrates a superior balance of **high performance** and **computational efficiency**.
* **Chart (a)** suggests that Kimi Linear is not just faster (high decoding acceleration) but also more accurate (high performance) on the RULER benchmark, breaking the typical trade-off between speed and quality. Its advantage on the MMLU-Pro benchmark, while smaller, is still present.
* **Chart (b)** provides the mechanistic reason for this efficiency: Kimi Linear's architecture results in a significantly lower time per output token, and this advantage becomes more pronounced with longer sequences. This indicates superior algorithmic or hardware utilization efficiency, making it particularly suitable for long-context applications where latency is critical.
* **Synthesis:** Together, the charts imply that Kimi Linear is a more scalable and effective solution for large language model inference, especially for tasks requiring both high accuracy on long-context evaluations (like RULER) and low-latency generation over very long sequences. The consistent outperformance across different metrics (accuracy, speed, latency scaling) suggests a fundamental architectural improvement over the MLA and GDN-H baselines.