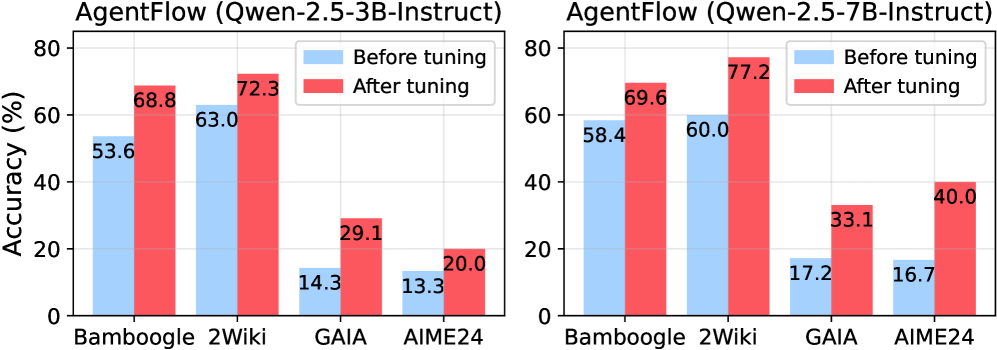
## Bar Chart: AgentFlow Accuracy Before and After Tuning
### Overview
The image contains two bar charts comparing the accuracy of AgentFlow models before and after tuning. The left chart represents the "Qwen-2.5-3B-Instruct" model, and the right chart represents the "Qwen-2.5-7B-Instruct" model. Both charts display accuracy (%) on the y-axis and different datasets (Bamboogle, 2Wiki, GAIA, AIME24) on the x-axis. The charts compare the accuracy before tuning (light blue bars) and after tuning (red bars).
### Components/Axes
* **Titles:**
* Left Chart: "AgentFlow (Qwen-2.5-3B-Instruct)"
* Right Chart: "AgentFlow (Qwen-2.5-7B-Instruct)"
* **Y-axis:**
* Label: "Accuracy (%)"
* Scale: 0 to 80, with increments of 20.
* **X-axis:**
* Categories: Bamboogle, 2Wiki, GAIA, AIME24
* **Legend:** Located at the top-right of each chart.
* Light Blue: "Before tuning"
* Red: "After tuning"
### Detailed Analysis
**Left Chart: AgentFlow (Qwen-2.5-3B-Instruct)**
* **Bamboogle:**
* Before tuning (light blue): 53.6%
* After tuning (red): 68.8%
* Trend: Accuracy increases after tuning.
* **2Wiki:**
* Before tuning (light blue): 63.0%
* After tuning (red): 72.3%
* Trend: Accuracy increases after tuning.
* **GAIA:**
* Before tuning (light blue): 14.3%
* After tuning (red): 29.1%
* Trend: Accuracy increases after tuning.
* **AIME24:**
* Before tuning (light blue): 13.3%
* After tuning (red): 20.0%
* Trend: Accuracy increases after tuning.
**Right Chart: AgentFlow (Qwen-2.5-7B-Instruct)**
* **Bamboogle:**
* Before tuning (light blue): 58.4%
* After tuning (red): 69.6%
* Trend: Accuracy increases after tuning.
* **2Wiki:**
* Before tuning (light blue): 60.0%
* After tuning (red): 77.2%
* Trend: Accuracy increases after tuning.
* **GAIA:**
* Before tuning (light blue): 17.2%
* After tuning (red): 33.1%
* Trend: Accuracy increases after tuning.
* **AIME24:**
* Before tuning (light blue): 16.7%
* After tuning (red): 40.0%
* Trend: Accuracy increases after tuning.
### Key Observations
* In both charts, the "After tuning" accuracy (red bars) is consistently higher than the "Before tuning" accuracy (light blue bars) for all datasets.
* The 2Wiki dataset generally shows the highest accuracy for both models, both before and after tuning.
* The GAIA and AIME24 datasets show the lowest accuracy for both models, but there is a significant improvement after tuning.
* The Qwen-2.5-7B-Instruct model generally shows higher accuracy than the Qwen-2.5-3B-Instruct model, especially after tuning.
### Interpretation
The data clearly demonstrates that tuning significantly improves the accuracy of AgentFlow models across all tested datasets. The Qwen-2.5-7B-Instruct model appears to benefit more from tuning than the Qwen-2.5-3B-Instruct model, as evidenced by the larger increases in accuracy after tuning. The consistent improvement across all datasets suggests that the tuning process is effective in enhancing the models' performance regardless of the specific task or data distribution. The lower accuracy on GAIA and AIME24, even after tuning, might indicate that these datasets present more challenging tasks or require further optimization strategies.