\n
## Bar Chart: AgentFlow Accuracy Comparison
### Overview
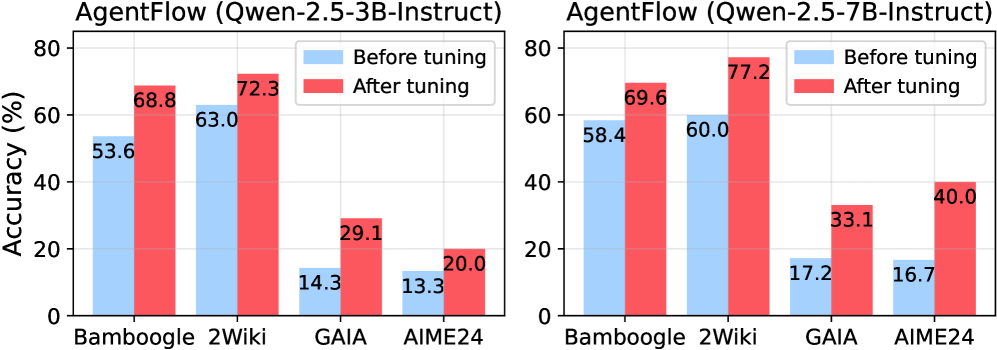
This image presents a comparative bar chart illustrating the accuracy of AgentFlow using two different models: Qwen-2.5-3B-Instruct and Qwen-2.5-7B-Instruct. The charts compare accuracy "Before tuning" and "After tuning" across four datasets: Bamboogle, 2Wiki, GAIA, and AIME24.
### Components/Axes
* **X-axis:** Datasets - Bamboogle, 2Wiki, GAIA, AIME24
* **Y-axis:** Accuracy (%) - Scale ranges from 0 to 80, with increments of 10.
* **Legend:**
* Light Blue: "Before tuning"
* Red: "After tuning"
* **Titles:**
* Left Chart: "AgentFlow (Qwen-2.5-3B-Instruct)"
* Right Chart: "AgentFlow (Qwen-2.5-7B-Instruct)"
### Detailed Analysis or Content Details
**Left Chart: AgentFlow (Qwen-2.5-3B-Instruct)**
* **Bamboogle:**
* Before tuning: Approximately 53.6%
* After tuning: Approximately 68.8%
* **2Wiki:**
* Before tuning: Approximately 63.0%
* After tuning: Approximately 72.3%
* **GAIA:**
* Before tuning: Approximately 14.3%
* After tuning: Approximately 29.1%
* **AIME24:**
* Before tuning: Approximately 13.3%
* After tuning: Approximately 20.0%
**Right Chart: AgentFlow (Qwen-2.5-7B-Instruct)**
* **Bamboogle:**
* Before tuning: Approximately 58.4%
* After tuning: Approximately 69.6%
* **2Wiki:**
* Before tuning: Approximately 60.0%
* After tuning: Approximately 77.2%
* **GAIA:**
* Before tuning: Approximately 17.2%
* After tuning: Approximately 33.1%
* **AIME24:**
* Before tuning: Approximately 16.7%
* After tuning: Approximately 40.0%
### Key Observations
* In both charts, "After tuning" consistently outperforms "Before tuning" across all datasets.
* The largest performance gains from tuning are observed on the GAIA and AIME24 datasets for both models.
* The 7B-Instruct model (right chart) generally achieves higher accuracy than the 3B-Instruct model (left chart) both before and after tuning.
* The 2Wiki dataset consistently shows the highest accuracy scores for both models.
### Interpretation
The data demonstrates that fine-tuning significantly improves the accuracy of AgentFlow for both the Qwen-2.5-3B-Instruct and Qwen-2.5-7B-Instruct models. The improvement is particularly pronounced on the GAIA and AIME24 datasets, suggesting these datasets present more challenging tasks that benefit significantly from the tuning process. The 7B-Instruct model's consistently higher accuracy indicates that a larger model size generally leads to better performance in this context. The high accuracy on the 2Wiki dataset suggests that AgentFlow is well-suited for tasks involving knowledge retrieval or processing from this specific dataset. The charts provide a clear quantitative comparison of the impact of model size and fine-tuning on AgentFlow's performance across different datasets, which is valuable for model selection and optimization.