\n
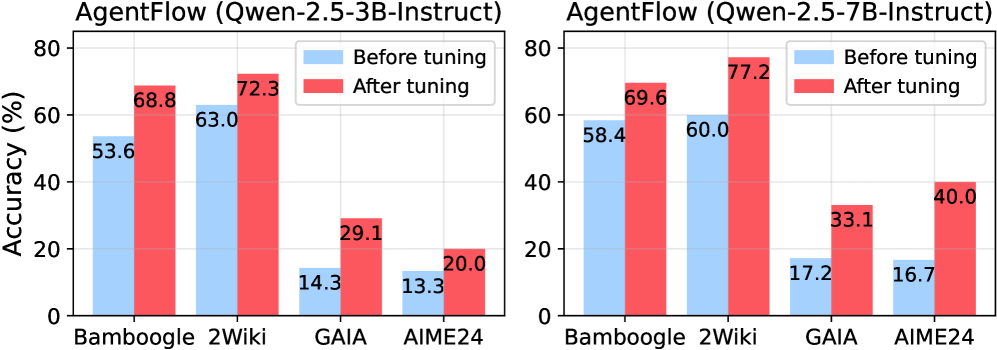
## Comparative Bar Charts: AgentFlow Model Accuracy Before and After Tuning
### Overview
The image displays two side-by-side bar charts comparing the performance accuracy (in percentage) of two different-sized language models ("AgentFlow") on four distinct benchmark datasets. The comparison is made between the models' performance "Before tuning" and "After tuning."
### Components/Axes
* **Chart Titles (Top):**
* Left Chart: `AgentFlow (Qwen-2.5-3B-Instruct)`
* Right Chart: `AgentFlow (Qwen-2.5-7B-Instruct)`
* **Y-Axis (Vertical):** Labeled `Accuracy (%)`. The scale runs from 0 to 80, with major tick marks at intervals of 20 (0, 20, 40, 60, 80).
* **X-Axis (Horizontal):** Lists four benchmark datasets for each chart: `Bamboogle`, `2Wiki`, `GAIA`, `AIME24`.
* **Legend (Top-right of each chart):**
* Light Blue Square: `Before tuning`
* Red Square: `After tuning`
### Detailed Analysis
**Left Chart: Qwen-2.5-3B-Instruct Model**
* **Trend Verification:** For all four datasets, the red bar ("After tuning") is taller than the light blue bar ("Before tuning"), indicating a universal improvement in accuracy post-tuning.
* **Data Points (Approximate values from labels):**
* **Bamboogle:** Before tuning ≈ 53.6%, After tuning ≈ 68.8%
* **2Wiki:** Before tuning ≈ 63.0%, After tuning ≈ 72.3%
* **GAIA:** Before tuning ≈ 14.3%, After tuning ≈ 29.1%
* **AIME24:** Before tuning ≈ 13.3%, After tuning ≈ 20.0%
**Right Chart: Qwen-2.5-7B-Instruct Model**
* **Trend Verification:** Similar to the 3B model, the red "After tuning" bars are consistently higher than the blue "Before tuning" bars across all datasets.
* **Data Points (Approximate values from labels):**
* **Bamboogle:** Before tuning ≈ 58.4%, After tuning ≈ 69.6%
* **2Wiki:** Before tuning ≈ 60.0%, After tuning ≈ 77.2%
* **GAIA:** Before tuning ≈ 17.2%, After tuning ≈ 33.1%
* **AIME24:** Before tuning ≈ 16.7%, After tuning ≈ 40.0%
### Key Observations
1. **Universal Improvement:** Tuning provides a positive accuracy boost for both model sizes on every tested benchmark.
2. **Model Size Correlation:** The larger 7B model generally starts with higher baseline accuracy (Before tuning) and achieves higher peak accuracy (After tuning) than the 3B model on the same datasets, with the most dramatic difference seen on the AIME24 benchmark.
3. **Dataset Difficulty:** The GAIA and AIME24 benchmarks appear significantly more challenging for both models, as indicated by their much lower accuracy scores (all below 41%) compared to Bamboogle and 2Wiki (all above 53%).
4. **Greatest Absolute Gain:** The largest single accuracy increase is observed for the 7B model on the AIME24 dataset, jumping approximately 23.3 percentage points (from 16.7% to 40.0%).
5. **Smallest Relative Gain:** The 3B model on the AIME24 dataset shows the smallest improvement, increasing by only about 6.7 percentage points.
### Interpretation
The data demonstrates the clear efficacy of the tuning process applied to the AgentFlow models. The consistent improvement across diverse benchmarks suggests the tuning successfully enhanced the models' general reasoning or task-specific capabilities. The performance gap between the 3B and 7B models highlights the expected benefit of increased model scale, but also shows that tuning can help a smaller model achieve respectable gains. The notably low scores on GAIA and AIME24, even after tuning, indicate these benchmarks likely test complex, multi-step reasoning or specialized knowledge that remains a challenge for these model architectures. The tuning appears particularly effective for the larger model on the hardest benchmark (AIME24), suggesting scale may be necessary to fully leverage the tuning process on highly difficult tasks.