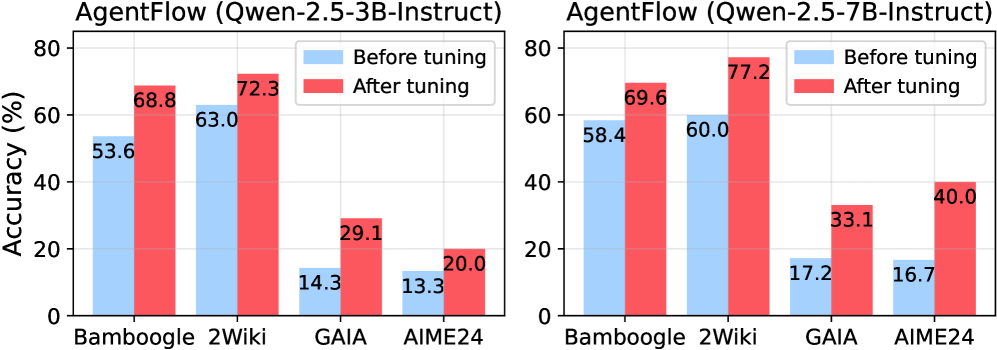
## Bar Chart: AgentFlow Accuracy Comparison (Qwen-2.5-3B-Instruct vs Qwen-2.5-7B-Instruct)
### Overview
The image contains two side-by-side bar charts comparing the accuracy of the AgentFlow system before and after tuning across four datasets: Bamboogle, 2Wiki, GAIA, and AIME24. The charts differentiate between two Qwen model versions (3B and 7B Instruct) and show performance improvements post-tuning.
### Components/Axes
- **X-axis**: Datasets (Bamboogle, 2Wiki, GAIA, AIME24)
- **Y-axis**: Accuracy (%) ranging from 0 to 80% in 20% increments
- **Legend**:
- Blue bars = "Before tuning"
- Red bars = "After tuning"
- **Chart Layout**: Two vertical bar charts placed side-by-side, each representing a Qwen model version.
### Detailed Analysis
#### Qwen-2.5-3B-Instruct (Left Chart)
| Dataset | Before Tuning (%) | After Tuning (%) |
|------------|-------------------|------------------|
| Bamboogle | 53.6 | 68.8 |
| 2Wiki | 63.0 | 72.3 |
| GAIA | 14.3 | 29.1 |
| AIME24 | 13.3 | 20.0 |
#### Qwen-2.5-7B-Instruct (Right Chart)
| Dataset | Before Tuning (%) | After Tuning (%) |
|------------|-------------------|------------------|
| Bamboogle | 58.4 | 69.6 |
| 2Wiki | 60.0 | 77.2 |
| GAIA | 17.2 | 33.1 |
| AIME24 | 16.7 | 40.0 |
### Key Observations
1. **Performance Gains**: All datasets show significant accuracy improvements after tuning for both models, with the 7B model consistently outperforming the 3B model.
2. **Dataset Variability**:
- 2Wiki demonstrates the highest post-tuning accuracy (77.2% for 7B model).
- GAIA and AIME24 show the largest relative improvements (e.g., GAIA jumps from 17.2% to 33.1% for 7B model).
3. **Baseline Disparity**: The 7B model starts with higher baseline accuracy across all datasets compared to the 3B model.
4. **AIME24 Anomaly**: Despite low initial performance (13.3-16.7%), AIME24 shows the most dramatic improvement (20-40% post-tuning).
### Interpretation
The data demonstrates that model tuning significantly enhances AgentFlow's performance, with the larger 7B model achieving higher absolute accuracy across all datasets. The consistent gains suggest that tuning optimizes the models' ability to handle diverse tasks, though GAIA and AIME24 remain challenging benchmarks. The 7B model's superior baseline performance indicates inherent advantages in scale, but both versions benefit similarly from tuning. The dramatic improvement in AIME24 suggests targeted tuning effectively addresses specific weaknesses in this dataset.