\n
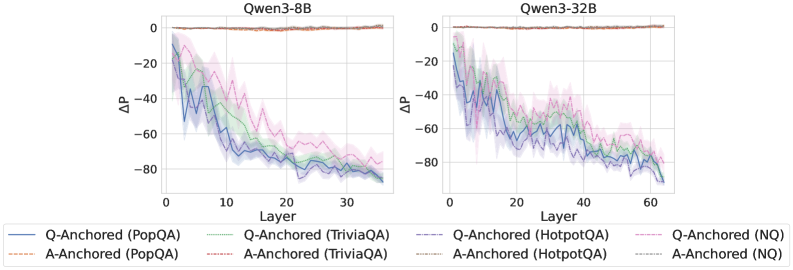
## Line Chart: ΔP vs. Layer for Qwen Models
### Overview
The image presents two line charts comparing the change in performance (ΔP) across different layers of two Qwen language models: Qwen3-8B and Qwen3-32B. The charts display performance differences for question-answering tasks using different anchoring methods (Q-Anchored and A-Anchored) and datasets (PopQA, TriviaQA, HotpotQA, and NQ). Each line represents a specific combination of anchoring method and dataset. The charts are positioned side-by-side for easy comparison.
### Components/Axes
* **X-axis:** Layer (ranging from 0 to approximately 35 for Qwen3-8B and 0 to approximately 65 for Qwen3-32B).
* **Y-axis:** ΔP (ranging from approximately -90 to 0).
* **Models:** Qwen3-8B (left chart), Qwen3-32B (right chart).
* **Legend:** Located at the bottom of the image, detailing the data series:
* Blue Line: Q-Anchored (PopQA)
* Orange Line: A-Anchored (PopQA)
* Green Line: Q-Anchored (TriviaQA)
* Purple Line: A-Anchored (TriviaQA)
* Brown Dashed Line: Q-Anchored (HotpotQA)
* Gray Dashed Line: A-Anchored (HotpotQA)
* Teal Line: Q-Anchored (NQ)
* Red Line: A-Anchored (NQ)
### Detailed Analysis or Content Details
**Qwen3-8B (Left Chart):**
* **Q-Anchored (PopQA) - Blue Line:** Starts at approximately -5, decreases steadily to approximately -80 by layer 35.
* **A-Anchored (PopQA) - Orange Line:** Starts at approximately -20, decreases to approximately -70 by layer 35.
* **Q-Anchored (TriviaQA) - Green Line:** Starts at approximately -10, decreases to approximately -75 by layer 35.
* **A-Anchored (TriviaQA) - Purple Line:** Starts at approximately -25, decreases to approximately -75 by layer 35.
* **Q-Anchored (HotpotQA) - Brown Dashed Line:** Starts at approximately -10, decreases to approximately -60 by layer 35.
* **A-Anchored (HotpotQA) - Gray Dashed Line:** Starts at approximately -20, decreases to approximately -65 by layer 35.
* **Q-Anchored (NQ) - Teal Line:** Starts at approximately -15, decreases to approximately -70 by layer 35.
* **A-Anchored (NQ) - Red Line:** Starts at approximately -25, decreases to approximately -75 by layer 35.
**Qwen3-32B (Right Chart):**
* **Q-Anchored (PopQA) - Blue Line:** Starts at approximately -5, decreases to approximately -80 by layer 65.
* **A-Anchored (PopQA) - Orange Line:** Starts at approximately -20, decreases to approximately -70 by layer 65.
* **Q-Anchored (TriviaQA) - Green Line:** Starts at approximately -10, decreases to approximately -75 by layer 65.
* **A-Anchored (TriviaQA) - Purple Line:** Starts at approximately -25, decreases to approximately -75 by layer 65.
* **Q-Anchored (HotpotQA) - Brown Dashed Line:** Starts at approximately -10, decreases to approximately -60 by layer 65.
* **A-Anchored (HotpotQA) - Gray Dashed Line:** Starts at approximately -20, decreases to approximately -65 by layer 65.
* **Q-Anchored (NQ) - Teal Line:** Starts at approximately -15, decreases to approximately -70 by layer 65.
* **A-Anchored (NQ) - Red Line:** Starts at approximately -25, decreases to approximately -75 by layer 65.
All lines in both charts exhibit a downward trend, indicating a decrease in ΔP as the layer number increases. The shaded areas around each line represent the uncertainty or variance in the data.
### Key Observations
* The performance decrease (ΔP) is more pronounced in the initial layers (0-20) for both models.
* The Q-Anchored methods generally start with higher ΔP values than the A-Anchored methods for all datasets.
* The HotpotQA dataset consistently shows the least negative ΔP values (closest to 0) across all layers and anchoring methods.
* The trends are remarkably similar between the Qwen3-8B and Qwen3-32B models, suggesting that increasing model size doesn't fundamentally alter the performance degradation pattern across layers.
* The uncertainty bands are relatively wide, especially in the initial layers, indicating higher variability in the performance measurements.
### Interpretation
The charts demonstrate a consistent performance degradation across layers for the Qwen models when evaluated on various question-answering datasets. This suggests that deeper layers may not contribute as significantly to performance on these tasks, or that the benefits of increased depth are offset by other factors like overfitting or vanishing gradients.
The difference between Q-Anchored and A-Anchored methods indicates that the method used to anchor the questions influences performance, with Q-Anchored generally performing better. The dataset-specific performance differences (HotpotQA being the least negative) suggest that the complexity and characteristics of the dataset play a role in how performance degrades across layers.
The similarity in trends between the 8B and 32B models is noteworthy. It implies that simply increasing model size does not necessarily address the underlying issue of performance degradation with depth. Further investigation is needed to understand the root cause of this phenomenon and explore techniques to mitigate it, such as more effective regularization or architectural modifications. The wide uncertainty bands suggest that the observed trends may not be statistically significant in some cases, and further experimentation with larger sample sizes may be necessary to confirm these findings.