\n
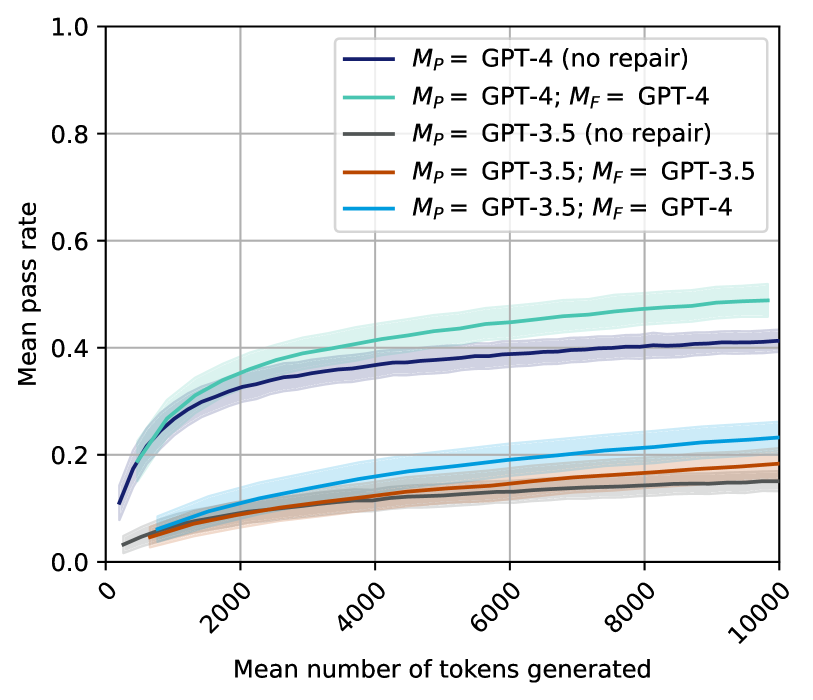
## Line Chart: Pass Rate vs. Tokens Generated for Different GPT Models
### Overview
This line chart depicts the relationship between the mean number of tokens generated and the mean pass rate for several configurations of GPT models. The chart compares the performance of GPT-4 and GPT-3.5, both with and without a "repair" mechanism (denoted by *M<sub>P</sub>* and *M<sub>F</sub>*). Shaded areas around each line represent uncertainty, likely standard deviation or confidence intervals.
### Components/Axes
* **X-axis:** "Mean number of tokens generated" - Scale ranges from 0 to 10000, with tick marks at 0, 2000, 4000, 6000, 8000, and 10000.
* **Y-axis:** "Mean pass rate" - Scale ranges from 0.0 to 1.0, with tick marks at 0.0, 0.2, 0.4, 0.6, 0.8, and 1.0.
* **Legend:** Located in the top-right corner of the chart. Contains the following labels and corresponding colors:
* Black: *M<sub>P</sub>* = GPT-4 (no repair)
* Gray: *M<sub>P</sub>* = GPT-4; *M<sub>F</sub>* = GPT-4
* Light Blue: *M<sub>P</sub>* = GPT-3.5 (no repair)
* Orange: *M<sub>P</sub>* = GPT-3.5; *M<sub>F</sub>* = GPT-3.5
* Blue: *M<sub>P</sub>* = GPT-3.5; *M<sub>F</sub>* = GPT-4
### Detailed Analysis
Here's a breakdown of each line's trend and approximate data points, verified against the legend colors:
* **GPT-4 (no repair) - Black Line:** The line starts at approximately (0, 0.05) and slopes upward, leveling off around (10000, 0.42). The shaded area indicates uncertainty, ranging from approximately 0.35 to 0.48 at 10000 tokens.
* **GPT-4; GPT-4 - Gray Line:** This line begins at approximately (0, 0.03) and exhibits a similar upward trend to GPT-4 (no repair), but remains consistently lower. It plateaus around (10000, 0.38), with a shaded uncertainty range of approximately 0.32 to 0.44.
* **GPT-3.5 (no repair) - Light Blue Line:** Starting at approximately (0, 0.02), this line shows a moderate upward slope, but is significantly lower than the GPT-4 lines. It reaches approximately (10000, 0.22), with a shaded uncertainty range of approximately 0.18 to 0.26.
* **GPT-3.5; GPT-3.5 - Orange Line:** This line begins at approximately (0, 0.01) and increases slowly, remaining the lowest of all lines. It plateaus around (10000, 0.18), with a shaded uncertainty range of approximately 0.14 to 0.22.
* **GPT-3.5; GPT-4 - Blue Line:** Starting at approximately (0, 0.04), this line shows a moderate upward slope, and is higher than the GPT-3.5; GPT-3.5 line, but lower than the GPT-4 lines. It plateaus around (10000, 0.35), with a shaded uncertainty range of approximately 0.30 to 0.40.
### Key Observations
* GPT-4 consistently outperforms GPT-3.5 across all token generation ranges.
* The "repair" mechanism (*M<sub>F</sub>*) appears to have a varying impact depending on the base model. When applied to GPT-3.5 with GPT-4 (*M<sub>P</sub>* = GPT-3.5; *M<sub>F</sub>* = GPT-4), it significantly improves the pass rate compared to GPT-3.5 alone.
* The uncertainty bands suggest that the pass rates are not highly predictable, and there is considerable variation in performance.
* The pass rate appears to plateau as the number of tokens generated increases, indicating diminishing returns.
### Interpretation
The data suggests that GPT-4 is a more reliable model for generating successful outputs (as measured by the pass rate) than GPT-3.5. The "repair" mechanism, represented by *M<sub>F</sub>*, seems to be most effective when combined with GPT-3.5 and GPT-4, suggesting a synergistic effect. The plateauing of the pass rate with increasing tokens indicates that there's a limit to how much improvement can be achieved by simply generating more text. The uncertainty bands highlight the inherent stochasticity of these models; even with the same input and settings, the output quality can vary.
The notation *M<sub>P</sub>* and *M<sub>F</sub>* likely refer to a "prompting" and "fixing" or "feedback" stage in the generation process. *M<sub>P</sub>* likely represents the initial model used for prompting, while *M<sub>F</sub>* represents a second model used to refine or "repair" the output. The results suggest that using a more powerful model (GPT-4) for the repair stage can significantly improve the overall pass rate, even when starting with a less powerful model (GPT-3.5).