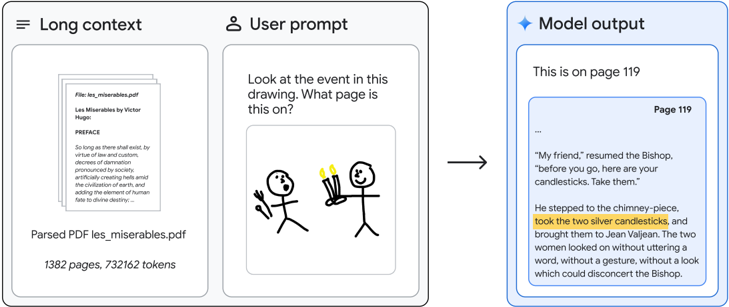
## Diagram: Multimodal AI Process Flow
### Overview
The image is a technical diagram illustrating a three-stage process for a multimodal AI system. It demonstrates how a long document (a PDF), a user's visual query (a drawing), and the model's textual output are connected. The diagram flows from left to right, showing input, processing, and output.
### Components/Axes
The diagram is segmented into three distinct vertical panels, each with a clear header and contained elements.
1. **Left Panel: "Long context"**
* **Header:** "Long context" (top-left).
* **Content:** A visual representation of a PDF document.
* **Document Details (Text):**
* `File: les_miserables.pdf`
* `Les Misérables by Victor Hugo`
* `PREFACE`
* A block of visible text from the preface begins: "So long as there shall exist, by reason of law and custom, a social condemnation..."
* **Metadata (Bottom):** `Parsed PDF les_miserables.pdf`, `1382 pages, 732162 tokens`.
2. **Center Panel: "User prompt"**
* **Header:** "User prompt" (top-center, with a user icon).
* **Content:** A two-part user query.
* **Text Query:** "Look at the event in this drawing. What page is this on?"
* **Visual Query (Drawing):** A simple line drawing depicting two stick figures.
* **Left Figure:** Holds a fork in its right hand.
* **Right Figure:** Holds two lit candles (candlesticks) in its left hand.
* The figures face each other.
3. **Right Panel: "Model output"**
* **Header:** "Model output" (top-right, with a sparkle icon).
* **Content:** The AI's generated response.
* **Direct Answer:** "This is on page 119"
* **Supporting Evidence:** A screenshot of a page from the PDF, labeled "Page 119" in its top-right corner.
* **Text Excerpt (Transcribed):**
> "My friend," resumed the Bishop,
> "before you go, here are your
> candlesticks. Take them."
>
> He stepped to the chimney-piece,
> **took the two silver candlesticks,**
> and brought them to Jean Valjean. The two
> women looked on without uttering a
> word, without a gesture, and without a look
> which could disconcert the Bishop.
* **Highlight:** The sentence "took the two silver candlesticks," is highlighted with a yellow background.
### Detailed Analysis
The diagram establishes a clear, linear workflow:
1. **Input 1 (Context):** A massive text document (1382 pages) is parsed and held in the model's long context window.
2. **Input 2 (Query):** The user provides a multimodal prompt combining a natural language question with a simple drawing that visually describes a specific event.
3. **Processing & Output:** The model processes both inputs. It interprets the drawing (recognizing the event of someone receiving candlesticks), searches its long context of the entire novel, and retrieves the precise page (119) and textual passage that corresponds to the visual event. The output provides both the direct answer and the corroborating source text.
### Key Observations
* **Direct Visual-Textual Correlation:** The drawing of a figure holding two candlesticks maps directly to the highlighted text "took the two silver candlesticks." This confirms the model's ability to perform cross-modal retrieval.
* **Scale of Context:** The system is explicitly shown handling a document of significant length (732,162 tokens), emphasizing the "long context" capability.
* **Precision of Retrieval:** The model doesn't just find a relevant chapter; it pinpoints the exact page number (119) and the specific sentence describing the event.
* **Spatial Layout:** The flow is strictly left-to-right, mirroring the logical sequence of data processing: Context + Prompt → Model → Output.
### Interpretation
This diagram is a functional demonstration of a **multimodal, long-context retrieval-augmented generation (RAG) system**. It argues that the AI can:
1. **Understand Visual Semantics:** Interpret a crude drawing to identify a narrative event (the giving of candlesticks).
2. **Leverage Vast Textual Memory:** Maintain and search through an entire novel held in its active context.
3. **Perform Precise Grounding:** Link a visual concept to its exact textual source, providing verifiable evidence (the page number and quote).
The inclusion of the PDF metadata (page/token count) and the specific page screenshot serves to validate the model's output, moving beyond a simple answer to providing **auditable proof**. The highlighted text acts as the critical link, closing the loop between the user's visual query and the model's textual evidence. The diagram's purpose is to showcase not just question-answering, but **evidence-based, cross-modal reasoning** over a large document.