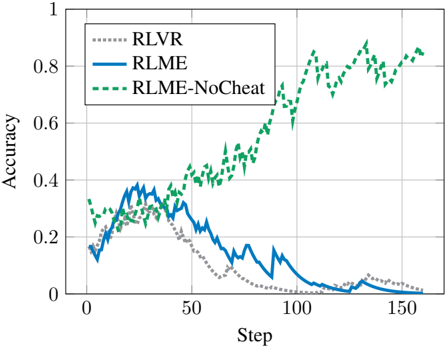
## Line Graph: Model Accuracy Over Training Steps
### Overview
The graph depicts the accuracy of three reinforcement learning models (RLVR, RLME, RLME-NoCheat) across 150 training steps. Accuracy is measured on a scale from 0 to 1, with distinct trends observed for each model.
### Components/Axes
- **X-axis (Step)**: Labeled "Step," with markers at 0, 50, 100, and 150.
- **Y-axis (Accuracy)**: Labeled "Accuracy," scaled from 0 to 1 in increments of 0.2.
- **Legend**: Located in the top-left corner, associating:
- **RLVR**: Dotted gray line
- **RLME**: Solid blue line
- **RLME-NoCheat**: Dashed green line
### Detailed Analysis
1. **RLVR (Dotted Gray Line)**:
- Starts at ~0.2 accuracy at step 0.
- Peaks at ~0.35 around step 25.
- Declines sharply to near 0 by step 150.
- Intermediate fluctuations observed between steps 50–100 (~0.1–0.2).
2. **RLME (Solid Blue Line)**:
- Begins at ~0.15 accuracy at step 0.
- Rises to ~0.4 around step 25.
- Gradual decline to ~0.1 by step 150.
- Notable volatility between steps 50–100 (~0.2–0.3).
3. **RLME-NoCheat (Dashed Green Line)**:
- Starts at ~0.2 accuracy at step 0.
- Steady upward trend, reaching ~0.8 by step 150.
- Minor fluctuations observed (e.g., ~0.75 at step 100, ~0.85 at step 125).
### Key Observations
- **RLME-NoCheat** consistently outperforms other models, maintaining high accuracy throughout training.
- **RLVR** and **RLME** exhibit early promise but degrade significantly over time, suggesting instability or overfitting.
- **RLME-NoCheat** shows resilience to training noise, with no sharp drops in accuracy.
### Interpretation
The data suggests that the "NoCheat" variant of RLME (RLME-NoCheat) is more robust and effective for this task, likely due to architectural or training modifications that mitigate overfitting. In contrast, RLVR and RLME degrade as training progresses, indicating potential issues with generalization or reward hacking. The steady rise of RLME-NoCheat implies it balances exploration and exploitation effectively, making it a preferable choice for long-term training scenarios.