\n
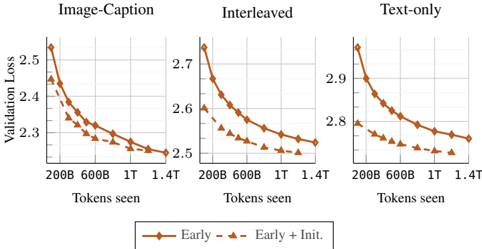
## Line Chart: Validation Loss vs. Tokens Seen for Different Training Strategies
### Overview
The image presents three line charts, each depicting the relationship between Validation Loss and Tokens Seen during training. Each chart represents a different training strategy: "Image-Caption", "Interleaved", and "Text-only". Each chart contains two lines representing different initialization methods ("Early" and "Early + Init."). The charts are arranged horizontally, side-by-side.
### Components/Axes
* **X-axis:** "Tokens seen" with markers at 200B, 600B, 1T, and 1.4T. (B = Billion, T = Trillion)
* **Y-axis:** "Validation Loss" ranging from approximately 2.3 to 2.9.
* **Legend:** Located at the bottom-center of the image.
* Solid Line: "Early" (represented by a dark orange color)
* Dashed Line: "Early + Init." (represented by a lighter orange color with triangle markers)
* **Titles:** Each chart has a title indicating the training strategy: "Image-Caption", "Interleaved", and "Text-only", positioned at the top-center of each chart.
### Detailed Analysis or Content Details
**Chart 1: Image-Caption**
* **Early (Solid Line):** The line slopes downward, indicating decreasing validation loss as tokens seen increase.
* 200B: Approximately 2.52
* 600B: Approximately 2.38
* 1T: Approximately 2.32
* 1.4T: Approximately 2.28
* **Early + Init. (Dashed Line):** The line also slopes downward, but starts at a lower validation loss than the "Early" line and remains consistently below it.
* 200B: Approximately 2.45
* 600B: Approximately 2.32
* 1T: Approximately 2.27
* 1.4T: Approximately 2.23
**Chart 2: Interleaved**
* **Early (Solid Line):** The line slopes downward.
* 200B: Approximately 2.70
* 600B: Approximately 2.58
* 1T: Approximately 2.50
* 1.4T: Approximately 2.45
* **Early + Init. (Dashed Line):** The line slopes downward, starting below the "Early" line.
* 200B: Approximately 2.62
* 600B: Approximately 2.50
* 1T: Approximately 2.43
* 1.4T: Approximately 2.38
**Chart 3: Text-only**
* **Early (Solid Line):** The line slopes downward.
* 200B: Approximately 2.90
* 600B: Approximately 2.80
* 1T: Approximately 2.75
* 1.4T: Approximately 2.70
* **Early + Init. (Dashed Line):** The line slopes downward, starting below the "Early" line.
* 200B: Approximately 2.83
* 600B: Approximately 2.73
* 1T: Approximately 2.68
* 1.4T: Approximately 2.63
### Key Observations
* In all three charts, the "Early + Init." line consistently exhibits lower validation loss than the "Early" line, suggesting that the initialization method improves performance.
* The "Text-only" training strategy consistently shows the highest validation loss across all tokens seen, indicating it is the least effective of the three strategies.
* The "Image-Caption" strategy consistently shows the lowest validation loss across all tokens seen, indicating it is the most effective of the three strategies.
* The rate of decrease in validation loss appears to slow down as the number of tokens seen increases in all charts, suggesting diminishing returns from further training.
### Interpretation
The data suggests that the initialization method ("Early + Init.") consistently improves model performance across all training strategies. The "Image-Caption" strategy yields the best results, likely due to the richer information provided by both image and text data. The "Text-only" strategy performs the worst, indicating that the model benefits significantly from visual information. The decreasing rate of validation loss reduction with increasing tokens seen suggests that the models are approaching convergence, and further training may not yield substantial improvements. The charts provide a comparative analysis of different training approaches and highlight the importance of both data modality and initialization techniques in achieving optimal model performance. The consistent gap between the "Early" and "Early + Init." lines suggests a systematic benefit from the initialization, rather than a random fluctuation.