TECHNICAL ASSET FINGERPRINT
5280a812eef8527de6e555fe
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
\n
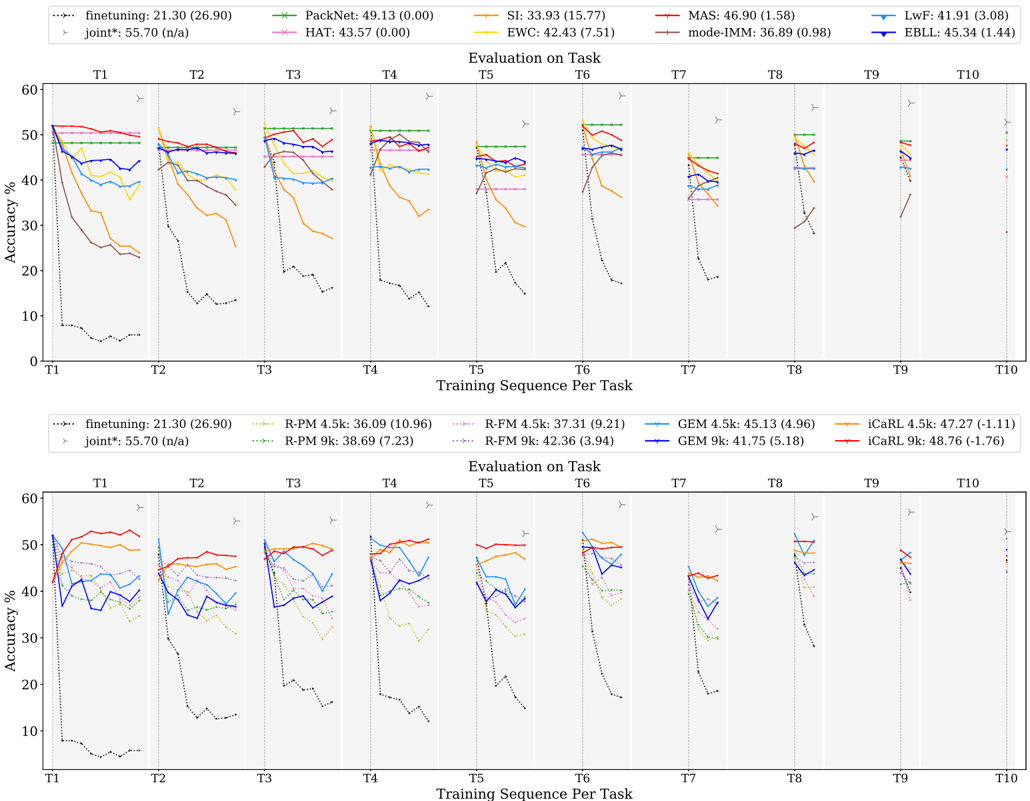
## Line Charts: Continual Learning Method Accuracy Across Sequential Tasks
### Overview
The image contains two vertically stacked line charts comparing the performance of various continual learning algorithms. Both charts plot "Accuracy %" against a "Training Sequence Per Task" (T1 through T10). Each chart has its own legend listing different methods and their associated performance metrics. The charts appear to be from a technical paper evaluating how well different machine learning models retain knowledge when learning new tasks sequentially.
### Components/Axes
**Common Elements (Both Charts):**
* **X-Axis:** Labeled "Training Sequence Per Task". Major tick marks are labeled T1, T2, T3, T4, T5, T6, T7, T8, T9, T10.
* **Y-Axis:** Labeled "Accuracy %". Scale runs from 0 to 60, with major ticks at 0, 10, 20, 30, 40, 50, 60.
* **Plot Title:** "Evaluation on Task" is centered above each plot area.
* **Grid:** Light gray vertical and horizontal grid lines are present.
**Top Chart Legend (Positioned at the top of the image, spanning horizontally):**
The legend lists 10 methods. Each entry shows a line style/marker, the method name, a primary number (likely mean accuracy), and a number in parentheses (likely standard deviation or another metric).
1. `--- finetuning: 21.30 (26.90)` (Black, dotted line)
2. `--- PackNet: 49.13 (0.00)` (Green line with 'x' markers)
3. `--- SI: 33.93 (15.77)` (Orange line)
4. `--- MAS: 46.90 (1.58)` (Red line)
5. `--- LwF: 41.91 (3.08)` (Light blue line)
6. `--- HAT: 43.57 (0.00)` (Pink line with '+' markers)
7. `--- EWC: 42.43 (7.51)` (Yellow line)
8. `--- mode-IMM: 36.89 (0.98)` (Brown line)
9. `--- EBLL: 45.34 (1.44)` (Dark blue line)
10. `--- joint*: 55.70 (n/a)` (Gray line with right-pointing triangle markers)
**Bottom Chart Legend (Positioned below the top chart's plot area):**
The legend lists 10 methods, comparing variants with "4.5k" and "9k" (likely memory buffer sizes).
1. `--- finetuning: 21.30 (26.90)` (Black, dotted line) - *Same as top chart.*
2. `--- R-PM 4.5k: 36.09 (10.96)` (Light green, dashed line)
3. `--- R-FM 4.5k: 37.31 (9.21)` (Pink, dashed line)
4. `--- GEM 4.5k: 45.13 (4.96)` (Light blue line)
5. `--- iCaRL 4.5k: 47.27 (-1.11)` (Orange line)
6. `--- R-PM 9k: 38.69 (7.23)` (Green, dashed line with 'x' markers)
7. `--- R-FM 9k: 42.36 (3.94)` (Pink, dashed line with '+' markers)
8. `--- GEM 9k: 41.75 (5.18)` (Dark blue line)
9. `--- iCaRL 9k: 48.76 (-1.76)` (Red line)
10. `--- joint*: 55.70 (n/a)` (Gray line with right-pointing triangle markers) - *Same as top chart.*
### Detailed Analysis
**Top Chart - Method Comparison:**
* **Trend Verification & Data Points:**
* **finetuning (Black dotted):** Starts near 50% at T1, then plummets dramatically to below 10% by T2 and remains very low (~5-15%) for all subsequent tasks. This shows catastrophic forgetting.
* **PackNet (Green, 'x'):** Maintains a very stable, high accuracy (~50%) across all tasks T1-T10. The line is nearly flat.
* **MAS (Red):** Starts high (~50%), shows a slight, gradual decline but remains above 40% through T10.
* **EBLL (Dark blue):** Similar trend to MAS, starting high and showing a moderate decline, ending in the mid-40s%.
* **HAT (Pink, '+'):** Starts high, shows a slight decline, and appears to stabilize around 40-45%.
* **LwF (Light blue):** Starts high, declines more noticeably than MAS/EBLL, ending near 40%.
* **EWC (Yellow):** Starts high, shows a significant decline, dropping to around 30% by T5 before a slight recovery.
* **SI (Orange):** Shows a steep decline similar to EWC, dropping from ~50% to the 20-30% range.
* **mode-IMM (Brown):** Starts lower than others (~45%), declines steadily to the 30-40% range.
* **joint* (Gray, triangles):** This appears to be an upper-bound baseline. It maintains a very high accuracy (~55%) across all tasks, consistently above all other methods.
**Bottom Chart - Memory Size Comparison (4.5k vs. 9k):**
* **Trend Verification & Data Points:**
* **finetuning (Black dotted):** Identical catastrophic forgetting trend as in the top chart.
* **joint* (Gray, triangles):** Identical high-performance baseline as in the top chart (~55%).
* **iCaRL (Orange 4.5k / Red 9k):** Both variants perform well. The 9k version (Red) consistently outperforms the 4.5k version (Orange) by a small margin (approx. 1-3%), maintaining accuracy near 50%.
* **GEM (Light blue 4.5k / Dark blue 9k):** The 4.5k version (Light blue) appears to have a slight edge over the 9k version (Dark blue) in later tasks, which is counter-intuitive. Both fluctuate between 35-50%.
* **R-FM (Pink dashed 4.5k / Pink dashed '+' 9k):** The 9k version shows a clear improvement over the 4.5k version, with the 9k line staying above 40% and the 4.5k line dropping into the 30s%.
* **R-PM (Light green dashed 4.5k / Green dashed 'x' 9k):** The 9k version shows a notable improvement over the 4.5k version. The 4.5k line drops significantly after T1, while the 9k line maintains higher accuracy.
### Key Observations
1. **Catastrophic Forgetting:** The `finetuning` method serves as a baseline for catastrophic forgetting, showing a severe and permanent drop in accuracy after the first task.
2. **Upper Bound:** The `joint*` method (likely trained on all data simultaneously) represents a performance ceiling (~55%) that sequential methods approach but do not exceed.
3. **Top Performers:** In the top chart, `PackNet` is the most stable and highest-performing sequential method, followed by `MAS` and `EBLL`. In the bottom chart, `iCaRL 9k` is the top-performing sequential method.
4. **Memory Benefit:** For `R-PM` and `R-FM`, increasing the memory buffer from 4.5k to 9k provides a clear performance benefit. The effect is less consistent or even reversed for `GEM` in this specific evaluation.
5. **Stability vs. Decline:** Methods like `PackNet` show remarkable stability (flat lines), while others like `SI` and `EWC` show a pronounced downward trend as more tasks are learned.
### Interpretation
This data demonstrates the core challenge of continual learning: preventing performance degradation on previously learned tasks while acquiring new ones. The stark contrast between `finetuning` and all other methods highlights the necessity of specialized algorithms.
The charts suggest that **regularization-based methods** (like MAS, EWC, SI) offer a middle ground, mitigating forgetting but often still experiencing a gradual decline. **Replay-based methods** (like iCaRL, GEM, R-PM, R-FM) show that maintaining a memory buffer is effective, and its size (4.5k vs. 9k) can be a critical hyperparameter, though its impact varies by algorithm. **Architectural methods** (like PackNet, which likely allocates separate network parameters per task) can achieve near-perfect knowledge retention, as shown by its flat line, but may have other trade-offs not measured here (e.g., model size).
The `joint*` baseline is crucial for context; it shows the maximum achievable accuracy if the model had access to all data at once. The gap between the best sequential methods (e.g., PackNet, iCaRL 9k) and this baseline represents the "cost" of learning sequentially. The goal of continual learning research, as visualized here, is to close this gap. The variability in performance across methods and tasks (seen in the jagged lines and different slopes) indicates that no single method is universally optimal, and performance is highly dependent on the specific algorithm and its configuration.
DECODING INTELLIGENCE...