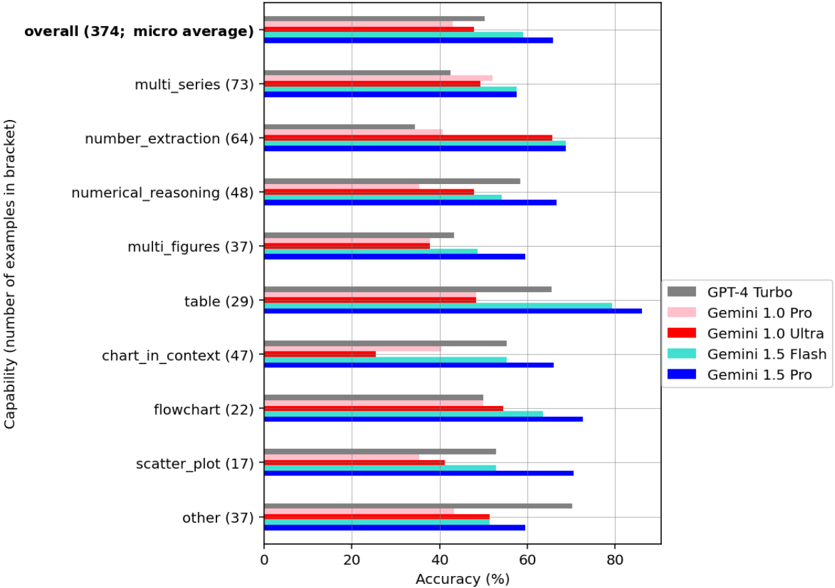
## Horizontal Bar Chart: Model Capability Comparison
### Overview
The image is a horizontal bar chart comparing the capabilities of five different language models (GPT-4 Turbo, Gemini 1.0 Pro, Gemini 1.0 Ultra, Gemini 1.5 Flash, and Gemini 1.5 Pro) across various tasks. The chart displays the accuracy (%) of each model on different tasks, with the number of examples used for each task indicated in brackets.
### Components/Axes
* **Y-axis (Capability):** Lists the different tasks or capabilities being evaluated. The number of examples used for each task is provided in parentheses. The tasks are:
* overall (374; micro average)
* multi\_series (73)
* number\_extraction (64)
* numerical\_reasoning (48)
* multi\_figures (37)
* table (29)
* chart\_in\_context (47)
* flowchart (22)
* scatter\_plot (17)
* other (37)
* **X-axis (Accuracy (%)):** Represents the accuracy of the models, ranging from 0% to 80% in increments of 20%.
* **Legend (Located in the bottom-right):** Identifies each language model with a specific color:
* GPT-4 Turbo: Gray
* Gemini 1.0 Pro: Pink
* Gemini 1.0 Ultra: Red
* Gemini 1.5 Flash: Cyan
* Gemini 1.5 Pro: Blue
### Detailed Analysis
Here's a breakdown of the accuracy for each model across the different tasks:
* **Overall (374; micro average):**
* GPT-4 Turbo (Gray): ~52%
* Gemini 1.0 Pro (Pink): ~48%
* Gemini 1.0 Ultra (Red): ~50%
* Gemini 1.5 Flash (Cyan): ~53%
* Gemini 1.5 Pro (Blue): ~72%
* **Multi\_series (73):**
* GPT-4 Turbo (Gray): ~42%
* Gemini 1.0 Pro (Pink): ~45%
* Gemini 1.0 Ultra (Red): ~43%
* Gemini 1.5 Flash (Cyan): ~40%
* Gemini 1.5 Pro (Blue): ~68%
* **Number\_extraction (64):**
* GPT-4 Turbo (Gray): ~38%
* Gemini 1.0 Pro (Pink): ~40%
* Gemini 1.0 Ultra (Red): ~58%
* Gemini 1.5 Flash (Cyan): ~60%
* Gemini 1.5 Pro (Blue): ~73%
* **Numerical\_reasoning (48):**
* GPT-4 Turbo (Gray): ~40%
* Gemini 1.0 Pro (Pink): ~25%
* Gemini 1.0 Ultra (Red): ~50%
* Gemini 1.5 Flash (Cyan): ~52%
* Gemini 1.5 Pro (Blue): ~70%
* **Multi\_figures (37):**
* GPT-4 Turbo (Gray): ~38%
* Gemini 1.0 Pro (Pink): ~30%
* Gemini 1.0 Ultra (Red): ~32%
* Gemini 1.5 Flash (Cyan): ~45%
* Gemini 1.5 Pro (Blue): ~68%
* **Table (29):**
* GPT-4 Turbo (Gray): ~35%
* Gemini 1.0 Pro (Pink): ~30%
* Gemini 1.0 Ultra (Red): ~70%
* Gemini 1.5 Flash (Cyan): ~75%
* Gemini 1.5 Pro (Blue): ~72%
* **Chart\_in\_context (47):**
* GPT-4 Turbo (Gray): ~45%
* Gemini 1.0 Pro (Pink): ~25%
* Gemini 1.0 Ultra (Red): ~30%
* Gemini 1.5 Flash (Cyan): ~40%
* Gemini 1.5 Pro (Blue): ~65%
* **Flowchart (22):**
* GPT-4 Turbo (Gray): ~40%
* Gemini 1.0 Pro (Pink): ~25%
* Gemini 1.0 Ultra (Red): ~50%
* Gemini 1.5 Flash (Cyan): ~55%
* Gemini 1.5 Pro (Blue): ~70%
* **Scatter\_plot (17):**
* GPT-4 Turbo (Gray): ~42%
* Gemini 1.0 Pro (Pink): ~30%
* Gemini 1.0 Ultra (Red): ~30%
* Gemini 1.5 Flash (Cyan): ~40%
* Gemini 1.5 Pro (Blue): ~65%
* **Other (37):**
* GPT-4 Turbo (Gray): ~45%
* Gemini 1.0 Pro (Pink): ~25%
* Gemini 1.0 Ultra (Red): ~40%
* Gemini 1.5 Flash (Cyan): ~40%
* Gemini 1.5 Pro (Blue): ~65%
### Key Observations
* Gemini 1.5 Pro (Blue) consistently outperforms the other models across all tasks, showing the highest accuracy in most categories.
* Gemini 1.0 Pro (Pink) generally has the lowest accuracy among the models.
* The performance of GPT-4 Turbo (Gray), Gemini 1.0 Ultra (Red), and Gemini 1.5 Flash (Cyan) varies depending on the specific task.
* The "table" task shows a significant performance boost for Gemini 1.0 Ultra and Gemini 1.5 Flash compared to other tasks.
### Interpretation
The bar chart provides a comparative analysis of the capabilities of different language models on a range of tasks. The data suggests that Gemini 1.5 Pro is the most capable model overall, demonstrating superior accuracy across various tasks. The performance variations across different tasks highlight the strengths and weaknesses of each model in specific areas. For instance, Gemini 1.0 Ultra and Gemini 1.5 Flash show a particular aptitude for handling tables. The chart is useful for understanding the relative performance of these models and identifying the most suitable model for specific applications. The number of examples in brackets indicates the robustness of the accuracy score.