\n
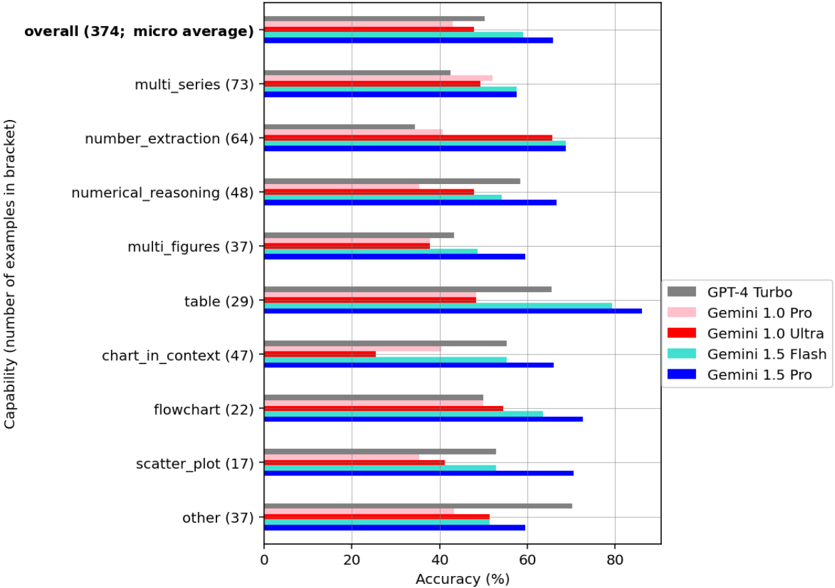
## Horizontal Bar Chart: Model Accuracy Across Capabilities
### Overview
This is a horizontal bar chart comparing the accuracy of several large language models (GPT-4 Turbo, Gemini 1.0 Pro, Gemini 1.0 Ultra, Gemini 1.5 Flash, and Gemini 1.5 Pro) across different capabilities. The capabilities are listed on the y-axis, and the accuracy is represented on the x-axis as a percentage. The number of examples used for each capability is indicated in brackets next to the capability name.
### Components/Axes
* **Y-axis (Vertical):** Capability (number of examples in brackets). Capabilities listed are: overall (374), multi\_series (73), number\_extraction (64), numerical\_reasoning (48), multi\_figures (37), table (29), chart\_in\_context (47), flowchart (22), scatter\_plot (17), other (37).
* **X-axis (Horizontal):** Accuracy (%) ranging from 0 to 80.
* **Legend (Top-Right):**
* GPT-4 Turbo (Grey)
* Gemini 1.0 Pro (Pink)
* Gemini 1.0 Ultra (Light Green)
* Gemini 1.5 Flash (Red)
* Gemini 1.5 Pro (Blue)
### Detailed Analysis
The chart consists of ten horizontal bars, each representing a different capability. For each capability, there are five bars representing the accuracy of the five models.
* **Overall:** GPT-4 Turbo ~74%, Gemini 1.0 Pro ~62%, Gemini 1.0 Ultra ~68%, Gemini 1.5 Flash ~70%, Gemini 1.5 Pro ~78%.
* **Multi\_series:** GPT-4 Turbo ~65%, Gemini 1.0 Pro ~55%, Gemini 1.0 Ultra ~60%, Gemini 1.5 Flash ~68%, Gemini 1.5 Pro ~74%.
* **Number\_extraction:** GPT-4 Turbo ~68%, Gemini 1.0 Pro ~50%, Gemini 1.0 Ultra ~62%, Gemini 1.5 Flash ~66%, Gemini 1.5 Pro ~76%.
* **Numerical\_reasoning:** GPT-4 Turbo ~60%, Gemini 1.0 Pro ~40%, Gemini 1.0 Ultra ~50%, Gemini 1.5 Flash ~60%, Gemini 1.5 Pro ~70%.
* **Multi\_figures:** GPT-4 Turbo ~55%, Gemini 1.0 Pro ~40%, Gemini 1.0 Ultra ~50%, Gemini 1.5 Flash ~58%, Gemini 1.5 Pro ~68%.
* **Table:** GPT-4 Turbo ~60%, Gemini 1.0 Pro ~45%, Gemini 1.0 Ultra ~55%, Gemini 1.5 Flash ~60%, Gemini 1.5 Pro ~70%.
* **Chart\_in\_context:** GPT-4 Turbo ~65%, Gemini 1.0 Pro ~50%, Gemini 1.0 Ultra ~60%, Gemini 1.5 Flash ~65%, Gemini 1.5 Pro ~75%.
* **Flowchart:** GPT-4 Turbo ~60%, Gemini 1.0 Pro ~45%, Gemini 1.0 Ultra ~55%, Gemini 1.5 Flash ~65%, Gemini 1.5 Pro ~75%.
* **Scatter\_plot:** GPT-4 Turbo ~60%, Gemini 1.0 Pro ~40%, Gemini 1.0 Ultra ~50%, Gemini 1.5 Flash ~60%, Gemini 1.5 Pro ~70%.
* **Other:** GPT-4 Turbo ~65%, Gemini 1.0 Pro ~45%, Gemini 1.0 Ultra ~55%, Gemini 1.5 Flash ~60%, Gemini 1.5 Pro ~70%.
### Key Observations
* Gemini 1.5 Pro consistently outperforms all other models across all capabilities.
* GPT-4 Turbo generally performs well, often second to Gemini 1.5 Pro.
* Gemini 1.0 Pro consistently has the lowest accuracy across all capabilities.
* The "overall" accuracy is relatively high for all models, suggesting a general level of competence.
* The number of examples varies significantly across capabilities, potentially influencing the reliability of the accuracy measurements.
### Interpretation
The data suggests that Gemini 1.5 Pro is the most capable model across a range of tasks, including multi-series analysis, number extraction, numerical reasoning, and understanding charts, flowcharts, and tables. The consistent outperformance of Gemini 1.5 Pro indicates a significant advancement in model capabilities. GPT-4 Turbo is a strong performer, but consistently lags behind Gemini 1.5 Pro. The lower accuracy of Gemini 1.0 Pro suggests it may be an older or less sophisticated model. The varying number of examples per capability introduces a potential bias, as accuracy estimates based on fewer examples may be less reliable. The "other" category, while having a moderate number of examples, shows similar performance trends to the other capabilities, reinforcing the overall ranking of the models. The chart demonstrates the rapid progress in large language model performance, particularly with the release of Gemini 1.5 Pro.