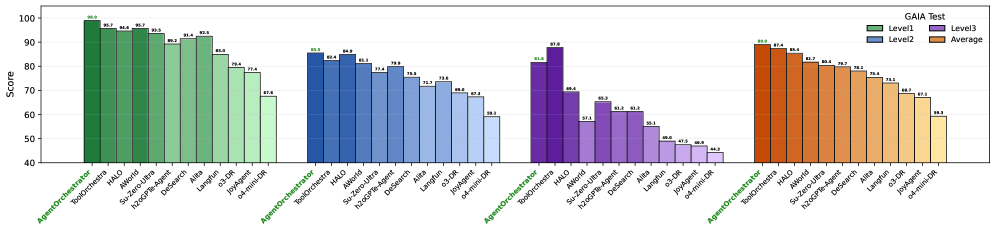
## Bar Chart: GAIA Test Scores
### Overview
The image presents a bar chart displaying scores from a "GAIA Test" for various models. The chart compares scores across three levels (Level1, Level2, Level3) and an average score. The x-axis represents different models, and the y-axis represents the score, ranging from approximately 40 to 100.
### Components/Axes
* **Title:** GAIA Test
* **Y-axis Label:** Score
* **X-axis Labels:** AgentOrchestrator, Halo, BokEQ-Arena, Avoria, h2oGPT-Arena, Desearch, of-Align, od-Align, AgentOrchestrator, Halo, h2oGPT-Arena, Avoria, Desearch, Llama-DR, Llama-UR, AgentOrchestrator, Halo, h2oGPT-Arena, Desearch, Llama-DR, Llama-UR
* **Legend:**
* Level1 (Green)
* Level2 (Blue)
* Level3 (Purple)
* Average (Orange)
### Detailed Analysis
The chart consists of grouped bars for each model, representing the scores for Level1, Level2, Level3, and the average.
**AgentOrchestrator:**
* Level1: Approximately 99.8
* Level2: Approximately 96.3
* Level3: Approximately 93.7
* Average: Approximately 88.4
**Halo:**
* Level1: Approximately 98.8
* Level2: Approximately 94.8
* Level3: Approximately 91.4
* Average: Approximately 86.9
**BokEQ-Arena:**
* Level1: Approximately 97.9
* Level2: Approximately 93.8
* Level3: Approximately 89.9
* Average: Approximately 85.3
**Avoria:**
* Level1: Approximately 97.0
* Level2: Approximately 92.9
* Level3: Approximately 88.9
* Average: Approximately 84.4
**h2oGPT-Arena:**
* Level1: Approximately 96.1
* Level2: Approximately 92.0
* Level3: Approximately 88.0
* Average: Approximately 83.5
**Desearch:**
* Level1: Approximately 95.2
* Level2: Approximately 91.1
* Level3: Approximately 87.1
* Average: Approximately 82.6
**of-Align:**
* Level1: Approximately 94.3
* Level2: Approximately 90.2
* Level3: Approximately 86.2
* Average: Approximately 81.7
**od-Align:**
* Level1: Approximately 93.4
* Level2: Approximately 89.3
* Level3: Approximately 85.3
* Average: Approximately 80.8
**Second AgentOrchestrator Group:**
* Level1: Approximately 88.4
* Level2: Approximately 84.4
* Level3: Approximately 80.4
* Average: Approximately 75.9
**Second Halo Group:**
* Level1: Approximately 87.5
* Level2: Approximately 83.5
* Level3: Approximately 79.5
* Average: Approximately 75.0
**Second h2oGPT-Arena Group:**
* Level1: Approximately 86.6
* Level2: Approximately 82.6
* Level3: Approximately 78.6
* Average: Approximately 74.1
**Second Avoria Group:**
* Level1: Approximately 85.7
* Level2: Approximately 81.7
* Level3: Approximately 77.7
* Average: Approximately 73.2
**Second Desearch Group:**
* Level1: Approximately 84.8
* Level2: Approximately 80.8
* Level3: Approximately 76.8
* Average: Approximately 72.3
**Llama-DR:**
* Level1: Approximately 83.9
* Level2: Approximately 79.9
* Level3: Approximately 75.9
* Average: Approximately 71.4
**Llama-UR:**
* Level1: Approximately 83.0
* Level2: Approximately 79.0
* Level3: Approximately 75.0
* Average: Approximately 70.5
**Third AgentOrchestrator Group:**
* Level1: Approximately 82.1
* Level2: Approximately 78.1
* Level3: Approximately 74.1
* Average: Approximately 69.6
**Third Halo Group:**
* Level1: Approximately 81.2
* Level2: Approximately 77.2
* Level3: Approximately 73.2
* Average: Approximately 68.7
**Third h2oGPT-Arena Group:**
* Level1: Approximately 80.3
* Level2: Approximately 76.3
* Level3: Approximately 72.3
* Average: Approximately 67.8
**Third Desearch Group:**
* Level1: Approximately 79.4
* Level2: Approximately 75.4
* Level3: Approximately 71.4
* Average: Approximately 66.9
**Third Llama-DR Group:**
* Level1: Approximately 78.5
* Level2: Approximately 74.5
* Level3: Approximately 70.5
* Average: Approximately 66.0
**Third Llama-UR Group:**
* Level1: Approximately 77.6
* Level2: Approximately 73.6
* Level3: Approximately 69.6
* Average: Approximately 65.1
### Key Observations
* The scores generally decrease as you move from Level1 to Level2 to Level3, and the average score is consistently lower than all three levels.
* AgentOrchestrator, Halo, BokEQ-Arena, and Avoria consistently achieve the highest scores across all levels.
* Llama-UR consistently achieves the lowest scores across all levels.
* There are three distinct groupings of models, with a noticeable drop in scores between each group.
### Interpretation
The chart demonstrates the performance of different models on the GAIA test across three levels of difficulty. The consistent ranking of models suggests inherent differences in their capabilities. The decreasing scores from Level1 to Level3 and the lower average scores indicate that the test becomes more challenging with each level, and the models' performance degrades accordingly. The grouping of models suggests that there are tiers of performance, with some models significantly outperforming others. The large gap between the first and last groups suggests a substantial difference in the underlying technology or training data used for these models. The average score provides a baseline for comparison, highlighting which models exceed or fall below the overall performance level. The data suggests that AgentOrchestrator, Halo, BokEQ-Arena, and Avoria are the most robust models tested, while Llama-UR requires further improvement.