## Flowchart: LLM Response Generation Process for Historical Queries
### Overview
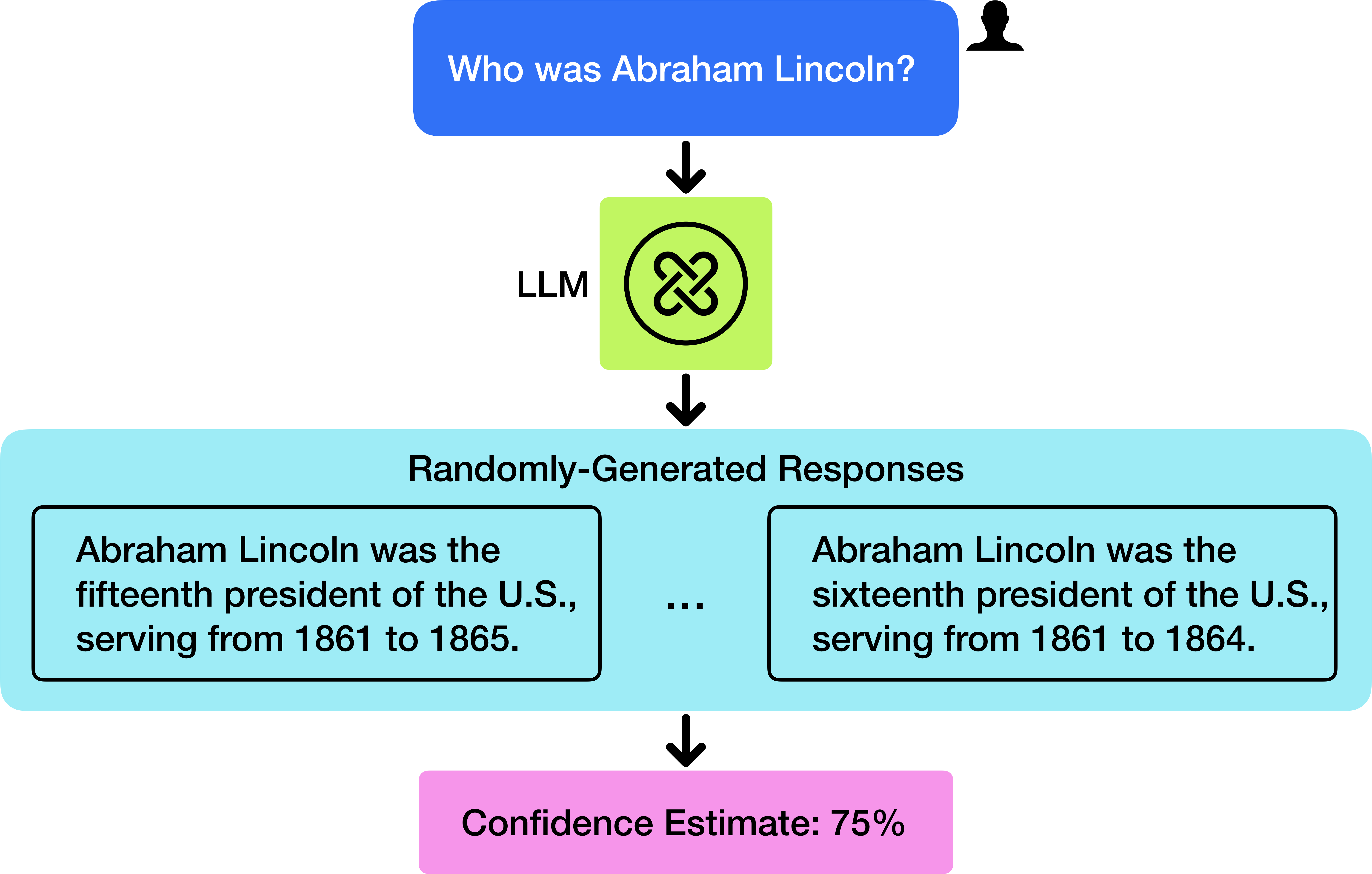
The diagram illustrates a simplified workflow of a Large Language Model (LLM) processing a historical query about Abraham Lincoln. It shows the input question, model processing, response generation, and confidence estimation.
### Components/Axes
1. **Input Question**:
- Blue box at top-center with text: "Who was Abraham Lincoln?"
- Adjacent user icon (silhouette) in top-right corner
2. **Model Processing**:
- Green box labeled "LLM" with a black knot symbol (infinity loop)
3. **Response Generation**:
- Light blue section containing two conflicting responses:
- Left box: "Abraham Lincoln was the fifteenth president of the U.S., serving from 1861 to 1865."
- Right box: "Abraham Lincoln was the sixteenth president of the U.S., serving from 1861 to 1864."
- Three ellipses (...) between responses indicate potential for multiple outputs
4. **Confidence Estimation**:
- Pink box at bottom-center with text: "Confidence Estimate: 75%"
### Detailed Analysis
- **Temporal Flow**:
- Top-to-bottom vertical progression from question → LLM → responses → confidence
- **Spatial Relationships**:
- Question box (blue) anchors top of diagram
- LLM processing (green) centrally located
- Response options (light blue) occupy middle section
- Confidence estimate (pink) anchors bottom
- **Textual Elements**:
- All text in English
- Numerical values: 15th/16th president, 1861-1865/1864 dates, 75% confidence
- No non-English text detected
### Key Observations
1. **Conflicting Information**:
- Responses contain contradictory presidential rankings (15th vs 16th)
- Date ranges overlap (1861-1864 vs 1861-1865)
2. **Confidence Paradox**:
- 75% confidence despite factual inconsistency in responses
3. **Structural Design**:
- Use of color coding (blue/green/light blue/pink) for visual hierarchy
- Arrows indicate deterministic flow despite random response generation
### Interpretation
This diagram reveals critical aspects of LLM behavior:
1. **Uncertainty Handling**:
- The model generates multiple responses despite factual contradictions, suggesting probabilistic output mechanisms
2. **Confidence Calibration**:
- 75% confidence despite factual errors indicates potential misalignment between confidence scores and factual accuracy
3. **Historical Knowledge Representation**:
- Conflicting responses highlight challenges in encoding precise historical timelines
4. **Process Transparency**:
- Visualization of internal LLM processes (question → processing → response generation → confidence) provides insight into AI decision-making
The diagram demonstrates both the capabilities and limitations of current LLM systems in handling historical queries, particularly regarding factual consistency and confidence calibration.