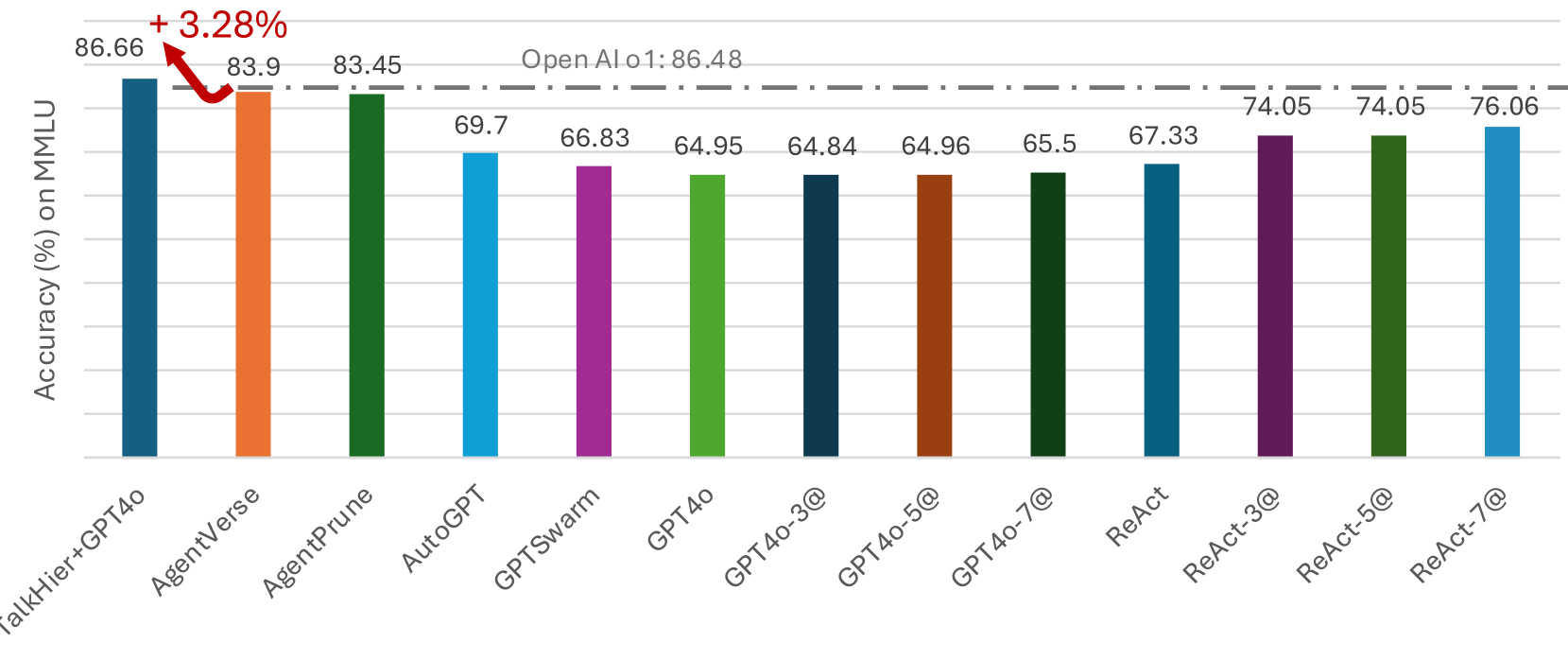
## Bar Chart: AI Model Accuracy Comparison on MMLU Benchmark
### Overview
The chart compares the accuracy (%) of various AI models on the MMLU (Massive Multitask Language Understanding) benchmark. It highlights performance differences between models, with a focus on GPT-4o variants, ReAct configurations, and experimental models like TalkHier+GPT4o and AgentVerse. A red arrow emphasizes a +3.28% increase between the OpenAI o1 baseline (86.48%) and the top-performing model.
### Components/Axes
- **X-axis**: AI models (categorical labels):
- TalkHier+GPT4o
- AgentVerse
- AgentPrune
- AutoGPT
- GPTSwarm
- GPT4o
- GPT4o-3@
- GPT4o-5@
- GPT4o-7@
- ReAct
- ReAct-3@
- ReAct-5@
- ReAct-7@
- **Y-axis**: Accuracy (%) on MMLU (numerical scale from 60% to 90%).
- **Bars**: Color-coded by model (e.g., blue for TalkHier+GPT4o, orange for AgentVerse, green for AgentPrune, etc.).
- **Annotations**:
- Red arrow labeled "+3.28%" pointing from OpenAI o1 (86.48%) to TalkHier+GPT4o (86.66%).
- Numerical values displayed atop each bar.
### Detailed Analysis
1. **Highest Performers**:
- **TalkHier+GPT4o**: 86.66% (blue bar, highest accuracy).
- **AgentVerse**: 83.9% (orange bar).
- **AgentPrune**: 83.45% (green bar).
- These models exceed the OpenAI o1 baseline (86.48%) by 0.18–3.28%.
2. **Mid-Range Models**:
- **AutoGPT**: 69.7% (light blue).
- **GPTSwarm**: 66.83% (purple).
- **GPT4o**: 64.95% (dark green).
- **GPT4o-3@**: 64.84% (dark blue).
- **GPT4o-5@**: 64.96% (brown).
- **GPT4o-7@**: 65.5% (dark green).
3. **ReAct Configurations**:
- **ReAct**: 74.05% (purple).
- **ReAct-3@**: 74.05% (purple).
- **ReAct-5@**: 74.05% (purple).
- **ReAct-7@**: 76.06% (blue).
4. **Notable Trends**:
- **GPT4o Variants**: All GPT4o models (base and scaled) cluster below 66%, indicating suboptimal performance compared to experimental models.
- **ReAct Improvements**: ReAct-7@ outperforms base ReAct by 2% (76.06% vs. 74.05%).
- **Experimental Models**: TalkHier+GPT4o and AgentVerse/AgentPrune significantly outperform OpenAI o1 and GPT4o variants.
### Key Observations
- **TalkHier+GPT4o** achieves the highest accuracy (86.66%), surpassing OpenAI o1 by 0.18%.
- **GPT4o-3@** and **GPT4o-5@** are the lowest performers (64.84–64.96%).
- **ReAct-7@** shows the strongest improvement among ReAct configurations.
- The +3.28% increase highlighted in the chart refers to the gap between OpenAI o1 (86.48%) and TalkHier+GPT4o (86.66%).
### Interpretation
The data suggests that experimental models like **TalkHier+GPT4o** and **AgentVerse/AgentPrune** outperform established baselines (OpenAI o1, GPT4o) on the MMLU benchmark. The ReAct framework demonstrates incremental gains with scaled configurations (e.g., ReAct-7@). However, GPT4o variants underperform relative to other models, raising questions about their optimization for this task. The +3.28% increase annotation emphasizes the competitive edge of TalkHier+GPT4o, though the difference is marginal. This chart underscores the importance of model architecture and configuration in achieving high accuracy on multitask language understanding.