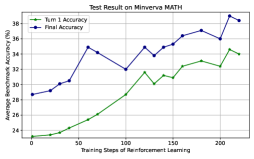
## Line Graph: Test Result on Minverva MATH
### Overview
The image is a line graph comparing two metrics—**Turn 1 Accuracy** (green line) and **Final Accuracy** (blue line)—across training steps of reinforcement learning. The x-axis represents training steps (0 to 200), and the y-axis represents average benchmark accuracy in percentage (24% to 38%). Both lines show upward trends, with **Final Accuracy** consistently outperforming **Turn 1 Accuracy**.
---
### Components/Axes
- **Title**: "Test Result on Minverva MATH" (top-center).
- **X-Axis**: "Training Steps of Reinforcement Learning" (0 to 200, increments of 50).
- **Y-Axis**: "Average Benchmark Accuracy (%)" (24% to 38%, increments of 2%).
- **Legend**: Top-left corner, with:
- Green circle: **Turn 1 Accuracy**
- Blue circle: **Final Accuracy**
---
### Detailed Analysis
#### Turn 1 Accuracy (Green Line)
- **Trend**: Steady upward slope with minor fluctuations.
- **Key Data Points**:
- 0 steps: ~23%
- 50 steps: ~25%
- 100 steps: ~28.5%
- 150 steps: ~31%
- 200 steps: ~34%
#### Final Accuracy (Blue Line)
- **Trend**: Volatile but overall upward trajectory with sharper increases.
- **Key Data Points**:
- 0 steps: ~28.5%
- 50 steps: ~34.5%
- 100 steps: ~32%
- 150 steps: ~35.5%
- 200 steps: ~38.5%
---
### Key Observations
1. **Final Accuracy** starts higher than **Turn 1 Accuracy** but shows greater variability (e.g., dips at 100 steps).
2. Both metrics improve significantly by 200 steps, with **Final Accuracy** reaching ~38.5% (peak) and **Turn 1 Accuracy** ~34%.
3. **Turn 1 Accuracy** exhibits a smoother, more linear progression compared to **Final Accuracy**.
---
### Interpretation
The graph demonstrates that reinforcement learning enhances performance over time for both metrics. **Final Accuracy** likely reflects iterative improvements or model refinement, explaining its higher variability but superior end result. The divergence between the two lines suggests that later training steps (e.g., after 100 steps) are critical for achieving peak performance. The consistent outperformance of **Final Accuracy** implies that reinforcement learning effectively optimizes outcomes beyond initial configurations.