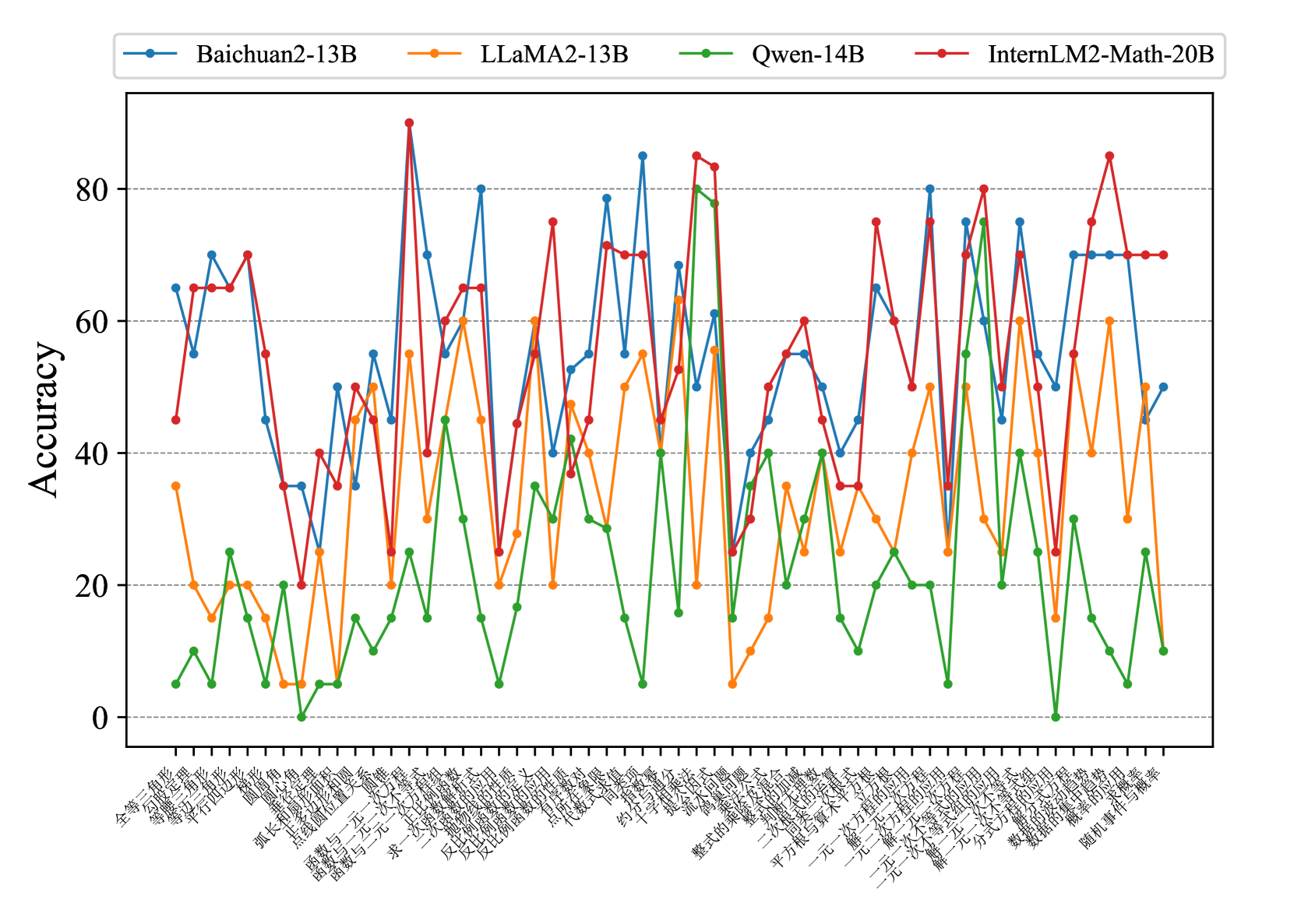
## Line Chart: Model Accuracy on Various Tasks
### Overview
This image presents a line chart comparing the accuracy of four large language models – Baichuan2-13B, LLaMA2-13B, Qwen-14B, and InternLM2-Math-20B – across a series of tasks. The x-axis represents different tasks, and the y-axis represents the accuracy score, ranging from 0 to 80.
### Components/Axes
* **Y-axis Title:** Accuracy
* **X-axis Title:** (Chinese characters - see Content Details for translation)
* **Legend:** Located at the top of the chart, identifying each line with a color and model name.
* Baichuan2-13B (Blue)
* LLaMA2-13B (Orange)
* Qwen-14B (Green)
* InternLM2-Math-20B (Red)
* **Gridlines:** Vertical gridlines are present to aid in reading values.
### Detailed Analysis
The x-axis labels are in Chinese. Here's a translation of the task names, to the best of my ability:
1. 全部 (All)
2. 写作 (Writing)
3. 翻译 (Translation)
4. 摘要 (Summary)
5. 问答 (Question Answering)
6. 头脑风暴 (Brainstorming)
7. 代码 (Code)
8. 文本分类 (Text Classification)
9. 情感分析 (Sentiment Analysis)
10. 命名实体识别 (Named Entity Recognition)
11. 文本匹配 (Text Matching)
12. 逻辑推理 (Logical Reasoning)
13. 知识问答 (Knowledge Question Answering)
14. 开放域问答 (Open Domain Question Answering)
15. 数学计算 (Mathematical Calculation)
16. 三元组抽取 (Triple Extraction)
17. 文本生成 (Text Generation)
18. 一元多项式求根 (Solving Univariate Polynomials)
19. 几何证明 (Geometric Proof)
20. 数学问题 (Math Problems)
21. 图形推理 (Graphical Reasoning)
22. 物理问答 (Physics Question Answering)
Here's a breakdown of each model's performance, with approximate values:
* **Baichuan2-13B (Blue):** Starts around 68% accuracy, dips to ~30% for 摘要, rises to ~82% for 文本分类, fluctuates between 40-80% for most tasks, and ends around 60% for 图形推理. Generally performs well, with several peaks above 70%.
* **LLaMA2-13B (Orange):** Starts around 65%, dips to ~25% for 摘要, peaks at ~85% for 文本分类, and generally stays between 30-60% for most tasks. Ends around 20% for 图形推理. Shows a strong peak for 文本分类 but is generally lower than Baichuan2-13B.
* **Qwen-14B (Green):** Starts very low at ~5%, rises to ~30% for 写作, fluctuates significantly between 10-40% for most tasks, and ends around 15% for 图形推理. Consistently the lowest performing model.
* **InternLM2-Math-20B (Red):** Starts around 65%, dips to ~30% for 写作, peaks at ~82% for 知识问答, and fluctuates between 40-80% for most tasks. Ends around 80% for 图形推理. Strong performance on mathematical and reasoning tasks.
### Key Observations
* **文本分类** consistently shows the highest accuracy for Baichuan2-13B and LLaMA2-13B, exceeding 80% for both.
* **Qwen-14B** consistently underperforms compared to the other three models across all tasks.
* **InternLM2-Math-20B** excels in tasks related to mathematical reasoning (数学计算, 一元多项式求根, 几何证明, 数学问题, 图形推理).
* The accuracy scores fluctuate considerably across different tasks for all models, indicating varying strengths and weaknesses.
* The "摘要" (Summary) task consistently results in lower accuracy for all models.
### Interpretation
The chart demonstrates a clear performance difference between the four language models. Baichuan2-13B and LLaMA2-13B are generally strong performers, while Qwen-14B lags behind. InternLM2-Math-20B stands out in mathematical and reasoning tasks, suggesting a specialized training focus. The variability in accuracy across tasks highlights the challenges of achieving consistent performance in diverse NLP applications. The low scores on the "摘要" task suggest that summarization remains a difficult problem for these models. The data suggests that model architecture and training data significantly impact performance on specific tasks. The high accuracy on "文本分类" for Baichuan2-13B and LLaMA2-13B could indicate a strong ability to discern patterns in text, while InternLM2-Math-20B's success in mathematical tasks points to a specialized mathematical reasoning capability.