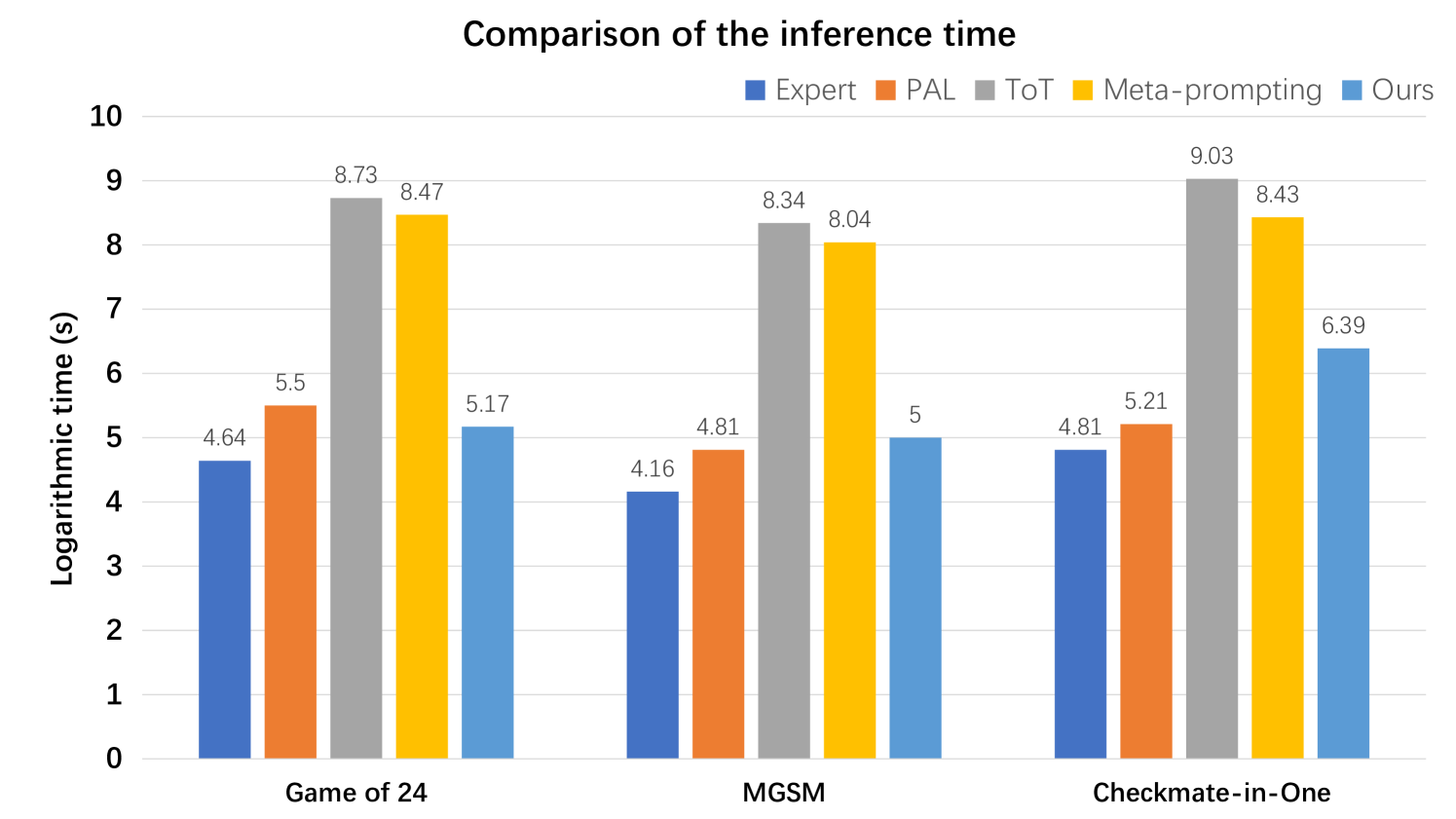
## Bar Chart: Comparison of the Inference Time
### Overview
The chart compares the logarithmic inference time (in seconds) of five methods—Expert, PAL, ToT, Meta-prompting, and Ours—across three games: Game of 24, MGSM, and Checkmate-in-One. The y-axis uses a logarithmic scale (0–10), emphasizing relative differences in performance.
### Components/Axes
- **X-axis**: Categorical labels for the three games:
- Game of 24
- MGSM
- Checkmate-in-One
- **Y-axis**: Logarithmic time (s), ranging from 0 to 10.
- **Legend**: Located in the top-right corner, mapping colors to methods:
- Blue: Expert
- Orange: PAL
- Gray: ToT
- Yellow: Meta-prompting
- Light Blue: Ours
### Detailed Analysis
#### Game of 24
- **Expert**: 4.64 (blue)
- **PAL**: 5.5 (orange)
- **ToT**: 8.73 (gray)
- **Meta-prompting**: 8.47 (yellow)
- **Ours**: 5.17 (light blue)
#### MGSM
- **Expert**: 4.16 (blue)
- **PAL**: 4.81 (orange)
- **ToT**: 8.34 (gray)
- **Meta-prompting**: 8.04 (yellow)
- **Ours**: 5.0 (light blue)
#### Checkmate-in-One
- **Expert**: 4.81 (blue)
- **PAL**: 5.21 (orange)
- **ToT**: 9.03 (gray)
- **Meta-prompting**: 8.43 (yellow)
- **Ours**: 6.39 (light blue)
### Key Observations
1. **ToT** consistently has the highest inference times across all games, with values ranging from 8.34 to 9.03.
2. **Meta-prompting** follows closely behind ToT, with slightly lower but still high times (8.04–8.47).
3. **Ours** (light blue) demonstrates the lowest inference times in all games, outperforming other methods by a significant margin.
4. **Expert** and **PAL** show moderate performance, with Expert generally faster than PAL.
5. The logarithmic scale highlights exponential differences, e.g., ToT’s 9.03 in Checkmate-in-One is ~1.5x slower than Meta-prompting’s 8.43.
### Interpretation
The data suggests that the method labeled "Ours" is the most efficient, achieving faster inference times than all other approaches. ToT and Meta-prompting, while slower, may prioritize accuracy or complexity over speed. The logarithmic scale emphasizes that even small numerical differences (e.g., 5.17 vs. 5.5) represent meaningful performance gaps. This chart likely evaluates trade-offs between speed and other factors (e.g., accuracy) in AI or computational models.