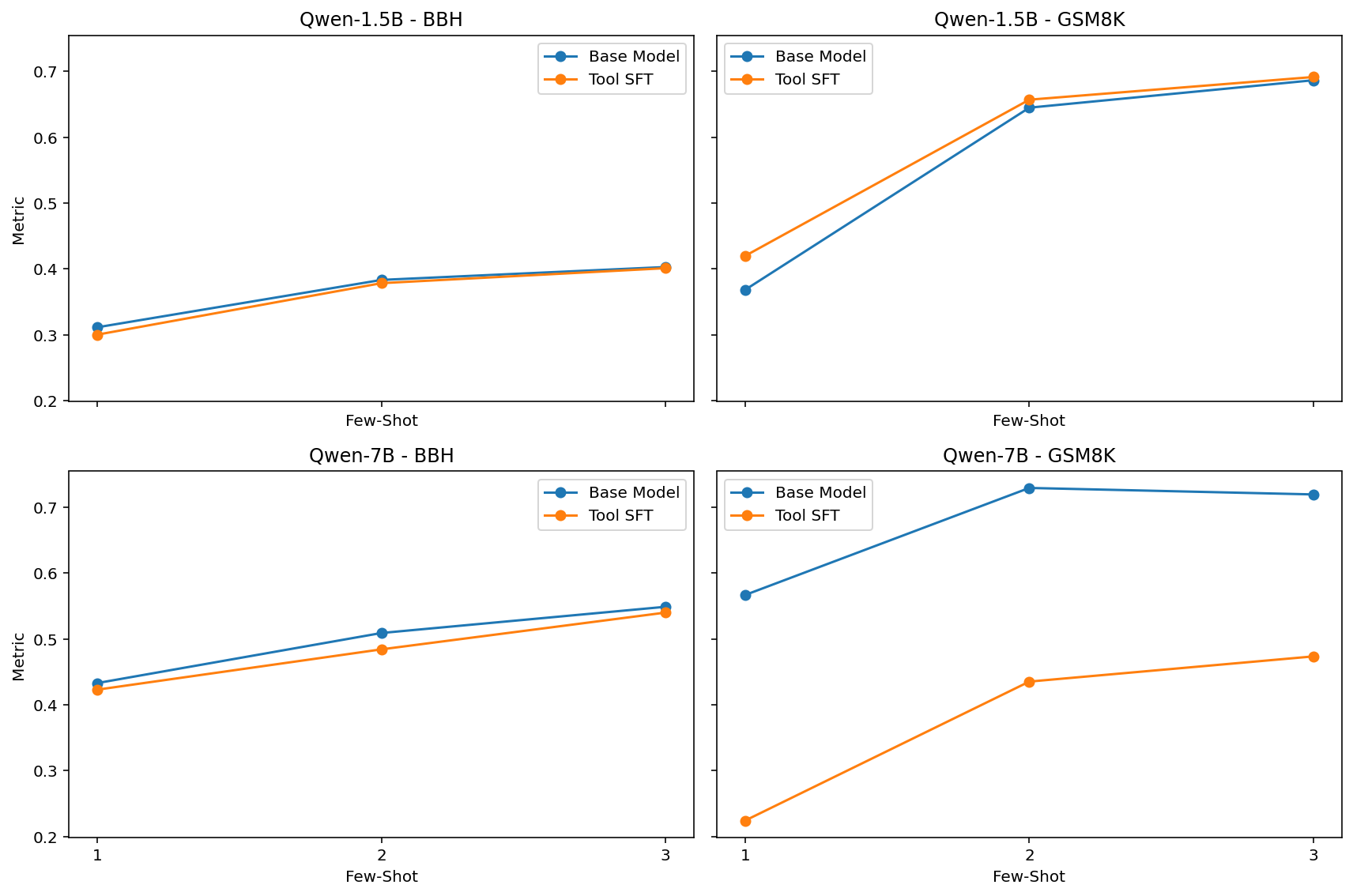
## Line Graphs: Qwen Model Performance Comparison Across Few-Shot Scenarios
### Overview
The image contains four line graphs comparing the performance of two models ("Base Model" and "Tool SFT") across different few-shot scenarios (1-shot, 2-shot, 3-shot) for two datasets: BBH and GSM8K. Each graph uses a y-axis labeled "Metric" (ranging from 0.2 to 0.7) and an x-axis labeled "Few-Shot" (with categories 1, 2, 3). The graphs are arranged in a 2x2 grid, with Qwen-1.5B and Qwen-7B models analyzed separately.
---
### Components/Axes
1. **Top-Left Chart**:
- **Title**: "Qwen-1.5B - BBH"
- **Legend**:
- Blue line: Base Model
- Orange line: Tool SFT
- **Axes**:
- X-axis: Few-Shot (1, 2, 3)
- Y-axis: Metric (0.2–0.7)
2. **Top-Right Chart**:
- **Title**: "Qwen-1.5B - GSM8K"
- **Legend**: Same as above.
- **Axes**: Same scale as top-left.
3. **Bottom-Left Chart**:
- **Title**: "Qwen-7B - BBH"
- **Legend**: Same as above.
- **Axes**: Same scale as top-left.
4. **Bottom-Right Chart**:
- **Title**: "Qwen-7B - GSM8K"
- **Legend**: Same as above.
- **Axes**: Same scale as top-left.
---
### Detailed Analysis
#### Qwen-1.5B - BBH (Top-Left)
- **Base Model (Blue)**:
- 1-shot: ~0.31
- 2-shot: ~0.39
- 3-shot: ~0.40
- **Tool SFT (Orange)**:
- 1-shot: ~0.30
- 2-shot: ~0.38
- 3-shot: ~0.40
- **Trend**: Both lines show a gradual upward slope, with Base Model consistently outperforming Tool SFT by ~0.01–0.02 across all shots.
#### Qwen-1.5B - GSM8K (Top-Right)
- **Base Model (Blue)**:
- 1-shot: ~0.37
- 2-shot: ~0.64
- 3-shot: ~0.68
- **Tool SFT (Orange)**:
- 1-shot: ~0.41
- 2-shot: ~0.65
- 3-shot: ~0.69
- **Trend**: Both lines exhibit a sharp increase from 1-shot to 2-shot, followed by a smaller rise to 3-shot. Tool SFT starts higher than Base Model but converges at 3-shot.
#### Qwen-7B - BBH (Bottom-Left)
- **Base Model (Blue)**:
- 1-shot: ~0.43
- 2-shot: ~0.51
- 3-shot: ~0.55
- **Tool SFT (Orange)**:
- 1-shot: ~0.42
- 2-shot: ~0.48
- 3-shot: ~0.54
- **Trend**: Both lines show a steady upward trajectory, with Base Model maintaining a ~0.01–0.02 advantage over Tool SFT.
#### Qwen-7B - GSM8K (Bottom-Right)
- **Base Model (Blue)**:
- 1-shot: ~0.57
- 2-shot: ~0.72
- 3-shot: ~0.71
- **Tool SFT (Orange)**:
- 1-shot: ~0.21
- 2-shot: ~0.43
- 3-shot: ~0.47
- **Trend**: Base Model starts high and plateaus slightly at 3-shot. Tool SFT begins very low but shows significant improvement, though it remains far below Base Model even at 3-shot.
---
### Key Observations
1. **Performance Gains with Few-Shot**:
- All models show improved performance as the number of shots increases, particularly in GSM8K.
- The largest gains occur between 1-shot and 2-shot (e.g., Qwen-1.5B GSM8K: Base Model jumps from 0.37 to 0.64).
2. **Model Size Impact**:
- Qwen-7B consistently outperforms Qwen-1.5B across all datasets and shot scenarios.
- In GSM8K, Qwen-7B Base Model achieves ~0.71 at 3-shot, compared to ~0.40 for Qwen-1.5B.
3. **Tool SFT Limitations**:
- Tool SFT underperforms Base Model in BBH across all models.
- In GSM8K, Tool SFT for Qwen-7B starts at 0.21 (1-shot) but improves to 0.47 (3-shot), still lagging behind Base Model.
4. **Dataset-Specific Behavior**:
- GSM8K appears more challenging, requiring more shots for convergence.
- BBH shows steadier, smaller improvements with additional shots.
---
### Interpretation
The data suggests that:
- **Few-Shot Learning Efficacy**: Increasing the number of examples (shots) significantly boosts performance, especially in complex tasks like GSM8K.
- **Model Size Matters**: Larger models (Qwen-7B) achieve higher metrics, indicating better generalization.
- **Tool SFT Trade-offs**: While Tool SFT improves performance, it often lags behind the Base Model, particularly in GSM8K. This could imply that Tool SFT is less effective for highly complex tasks or requires more data to match Base Model performance.
- **Anomalies**: The drastic drop in Tool SFT performance for Qwen-7B in GSM8K (1-shot: 0.21 vs. Base Model: 0.57) raises questions about initialization or training stability for this configuration.
These trends highlight the importance of model scale and task complexity in few-shot learning scenarios, with Base Models generally outperforming Tool SFT in challenging datasets like GSM8K.