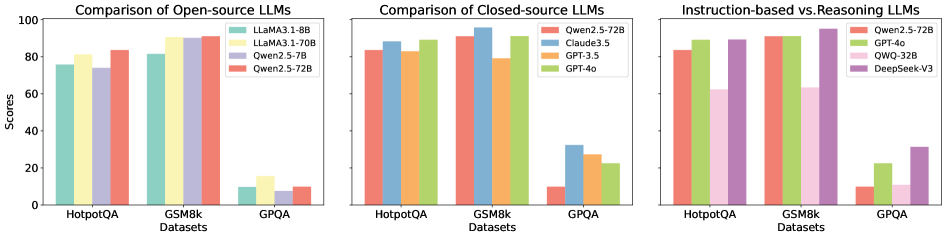
## Bar Chart: LLM Performance Comparison
### Overview
The image presents a comparative analysis of Large Language Models (LLMs) across three datasets: HotpotQA, GSM8k, and GPQA. It consists of three separate bar charts, each focusing on a different category of LLMs: Open-source LLMs, Closed-source LLMs, and a comparison of Instruction-based vs. Reasoning LLMs. The Y-axis represents "Scores," ranging from 0 to 100. The X-axis represents the datasets used for evaluation.
### Components/Axes
* **Y-axis:** "Scores" (Scale: 0 to 100, increments of 20)
* **X-axis:** "Datasets" (Categories: HotpotQA, GSM8k, GPQA)
* **Chart 1 (Open-source LLMs):**
* Legend:
* LLaMA3-1.8B (Blue)
* LLaMA3-1.70B (Yellow)
* Qwen2-5-7B (Light Blue)
* Qwen2-5-72B (Red)
* **Chart 2 (Closed-source LLMs):**
* Legend:
* Qwen2.5-72B (Orange)
* Claude3.5 (Green)
* GPT-3.5 (Yellow)
* GPT-4o (Brown)
* **Chart 3 (Instruction-based vs. Reasoning LLMs):**
* Legend:
* Qwen2.5-72B (Purple)
* GPT-4o (Green)
* QWQ-32B (Light Green)
* DeepSeek-V3 (Dark Green)
### Detailed Analysis or Content Details
**Chart 1: Comparison of Open-source LLMs**
* **HotpotQA:**
* LLaMA3-1.8B: Approximately 75
* LLaMA3-1.70B: Approximately 70
* Qwen2-5-7B: Approximately 72
* Qwen2-5-72B: Approximately 68
* **GSM8k:**
* LLaMA3-1.8B: Approximately 95
* LLaMA3-1.70B: Approximately 92
* Qwen2-5-7B: Approximately 90
* Qwen2-5-72B: Approximately 88
* **GPQA:**
* LLaMA3-1.8B: Approximately 15
* LLaMA3-1.70B: Approximately 12
* Qwen2-5-7B: Approximately 10
* Qwen2-5-72B: Approximately 8
**Chart 2: Comparison of Closed-source LLMs**
* **HotpotQA:**
* Qwen2.5-72B: Approximately 80
* Claude3.5: Approximately 85
* GPT-3.5: Approximately 78
* GPT-4o: Approximately 82
* **GSM8k:**
* Qwen2.5-72B: Approximately 95
* Claude3.5: Approximately 98
* GPT-3.5: Approximately 90
* GPT-4o: Approximately 99
* **GPQA:**
* Qwen2.5-72B: Approximately 25
* Claude3.5: Approximately 22
* GPT-3.5: Approximately 15
* GPT-4o: Approximately 30
**Chart 3: Instruction-based vs. Reasoning LLMs**
* **HotpotQA:**
* Qwen2.5-72B: Approximately 80
* GPT-4o: Approximately 85
* QWQ-32B: Approximately 75
* DeepSeek-V3: Approximately 70
* **GSM8k:**
* Qwen2.5-72B: Approximately 95
* GPT-4o: Approximately 98
* QWQ-32B: Approximately 90
* DeepSeek-V3: Approximately 85
* **GPQA:**
* Qwen2.5-72B: Approximately 10
* GPT-4o: Approximately 15
* QWQ-32B: Approximately 5
* DeepSeek-V3: Approximately 8
### Key Observations
* GPT-4o consistently achieves the highest scores across all datasets in the Closed-source and Instruction-based vs. Reasoning LLMs charts.
* Claude3.5 performs very well, often close to GPT-4o, particularly on GSM8k.
* LLaMA3-1.8B generally outperforms the other open-source models, especially on GSM8k.
* All models struggle on the GPQA dataset, with scores significantly lower than on HotpotQA and GSM8k.
* The gap in performance between open-source and closed-source models is noticeable, with closed-source models generally achieving higher scores.
### Interpretation
The data suggests that GPT-4o is currently the leading LLM in terms of performance on these datasets, followed closely by Claude3.5. The open-source models are improving, with LLaMA3-1.8B showing promising results, but still lag behind the closed-source counterparts. The consistent low scores on GPQA indicate that this dataset presents a significant challenge for all models, potentially due to its specific characteristics or complexity.
The comparison between instruction-based and reasoning LLMs highlights the importance of both capabilities for achieving high performance. GPT-4o again leads in this category, suggesting a strong balance between instruction following and reasoning abilities. The differences in performance between the models on each dataset could be attributed to variations in their training data, model architecture, and optimization strategies. The data provides valuable insights for researchers and developers working on LLMs, guiding future efforts to improve model performance and address the challenges posed by different datasets.