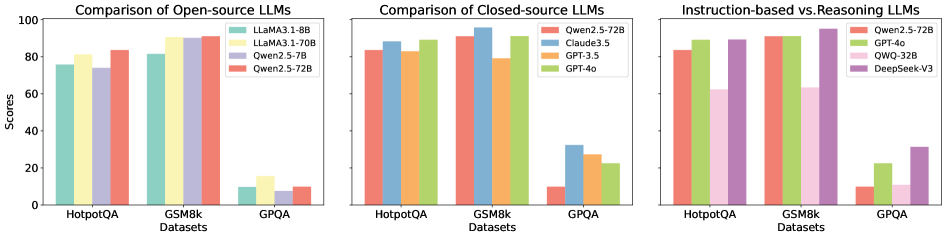
## [Grouped Bar Charts]: LLM Performance Comparison Across Datasets
### Overview
The image displays three side-by-side grouped bar charts comparing the performance of various Large Language Models (LLMs) on three benchmark datasets: HotpotQA, GSM8k, and GPQA. The charts are titled "Comparison of Open-source LLMs," "Comparison of Closed-source LLMs," and "Instruction-based vs Reasoning LLMs." Each chart uses a consistent y-axis labeled "Scores" ranging from 0 to 100.
### Components/Axes
**Common Elements:**
* **Y-Axis:** Labeled "Scores" with major tick marks at 0, 20, 40, 60, 80, and 100.
* **X-Axis:** Labeled "Datasets" with three categories: "HotpotQA", "GSM8k", and "GPQA".
* **Chart Titles:** Located at the top of each respective chart.
* **Legends:** Positioned in the top-right corner of each chart area.
**Chart 1: Comparison of Open-source LLMs**
* **Legend (Top-Right):**
* Teal bar: `LLaMA3.1-8B`
* Light yellow bar: `LLaMA3.1-70B`
* Light purple bar: `Qwen2.5-7B`
* Red bar: `Qwen2.5-72B`
**Chart 2: Comparison of Closed-source LLMs**
* **Legend (Top-Right):**
* Red bar: `Qwen2.5-72B`
* Blue bar: `Claude3.5`
* Orange bar: `GPT-3.5`
* Green bar: `GPT-4o`
**Chart 3: Instruction-based vs Reasoning LLMs**
* **Legend (Top-Right):**
* Red bar: `Qwen2.5-72B`
* Green bar: `GPT-4o`
* Light pink bar: `QWO-32B`
* Purple bar: `DeepSeek-V3`
### Detailed Analysis
**Chart 1: Comparison of Open-source LLMs**
* **HotpotQA:** All models score between ~75 and ~85. `LLaMA3.1-70B` (light yellow) appears highest (~85), followed closely by `Qwen2.5-72B` (red, ~83), `LLaMA3.1-8B` (teal, ~78), and `Qwen2.5-7B` (light purple, ~75).
* **GSM8k:** Scores are generally higher. `LLaMA3.1-70B` (light yellow) is the highest (~92), followed by `Qwen2.5-72B` (red, ~88), `Qwen2.5-7B` (light purple, ~85), and `LLaMA3.1-8B` (teal, ~82).
* **GPQA:** All models show a significant performance drop. `LLaMA3.1-70B` (light yellow) is highest (~15), followed by `Qwen2.5-72B` (red, ~10), `LLaMA3.1-8B` (teal, ~8), and `Qwen2.5-7B` (light purple, ~5).
**Chart 2: Comparison of Closed-source LLMs**
* **HotpotQA:** `GPT-4o` (green) leads (~88), followed by `Claude3.5` (blue, ~85), `Qwen2.5-72B` (red, ~83), and `GPT-3.5` (orange, ~82).
* **GSM8k:** `GPT-4o` (green) is highest (~95), followed by `Claude3.5` (blue, ~92), `Qwen2.5-72B` (red, ~88), and `GPT-3.5` (orange, ~80).
* **GPQA:** Performance is low across the board. `Claude3.5` (blue) is highest (~32), followed by `GPT-3.5` (orange, ~28), `GPT-4o` (green, ~22), and `Qwen2.5-72B` (red, ~10).
**Chart 3: Instruction-based vs Reasoning LLMs**
* **HotpotQA:** `GPT-4o` (green) and `DeepSeek-V3` (purple) are tied for highest (~88), followed by `Qwen2.5-72B` (red, ~83), and `QWO-32B` (light pink, ~62).
* **GSM8k:** `GPT-4o` (green) is highest (~95), followed by `Qwen2.5-72B` (red, ~88), `DeepSeek-V3` (purple, ~65), and `QWO-32B` (light pink, ~62).
* **GPQA:** `DeepSeek-V3` (purple) is highest (~32), followed by `GPT-4o` (green, ~22), `QWO-32B` (light pink, ~10), and `Qwen2.5-72B` (red, ~10).
### Key Observations
1. **Dataset Difficulty:** All models, regardless of type (open-source, closed-source, instruction/reasoning), perform significantly worse on the GPQA dataset compared to HotpotQA and GSM8k. This suggests GPQA is a more challenging benchmark.
2. **Model Scaling:** Within the open-source models, the 70B/72B parameter models (`LLaMA3.1-70B`, `Qwen2.5-72B`) consistently outperform their smaller counterparts (`LLaMA3.1-8B`, `Qwen2.5-7B`) across all datasets.
3. **Top Performers:** `GPT-4o` (green) is a top performer in the closed-source and instruction/reasoning charts, especially on GSM8k. `LLaMA3.1-70B` (light yellow) is the top performer among the open-source models shown.
4. **Qwen2.5-72B as a Common Reference:** The `Qwen2.5-72B` model (red bar) appears in all three charts, allowing for a cross-comparison. Its performance is competitive with top open-source models and some closed-source models, but it is outperformed by `GPT-4o` and `Claude3.5` on most tasks.
5. **Specialization:** `DeepSeek-V3` (purple) shows a notable strength on the GPQA dataset relative to other models in its chart, suggesting potential specialization in that type of reasoning task.
### Interpretation
This set of charts provides a snapshot of the competitive landscape among LLMs circa the data's collection (likely pre-May 2025). The data demonstrates several key trends:
* **The Scaling Law in Action:** The clear performance advantage of larger models (70B/72B vs. 8B/7B) empirically supports the principle that model scale is a primary driver of capability on standard benchmarks.
* **The "GPQA Gap":** The universal drop in scores on GPQA indicates this benchmark tests a dimension of reasoning or knowledge that is not as well-captured by the training or optimization of these models compared to HotpotQA (multi-hop reasoning) and GSM8k (mathematical reasoning). It highlights an area for future model improvement.
* **The Closed-Source Edge:** While open-source models like `LLaMA3.1-70B` are highly capable, the top closed-source models (`GPT-4o`, `Claude3.5`) generally maintain a performance lead, particularly on the GSM8k math benchmark. This suggests potential advantages in training data, methodology, or compute resources.
* **Task-Specific Strengths:** The variation in model rankings across datasets (e.g., `DeepSeek-V3` on GPQA, `GPT-4o` on GSM8k) implies that no single model is universally superior. Model selection should be guided by the specific task or domain, as different architectures and training approaches yield different strengths.
**Language Note:** All text in the image is in English.