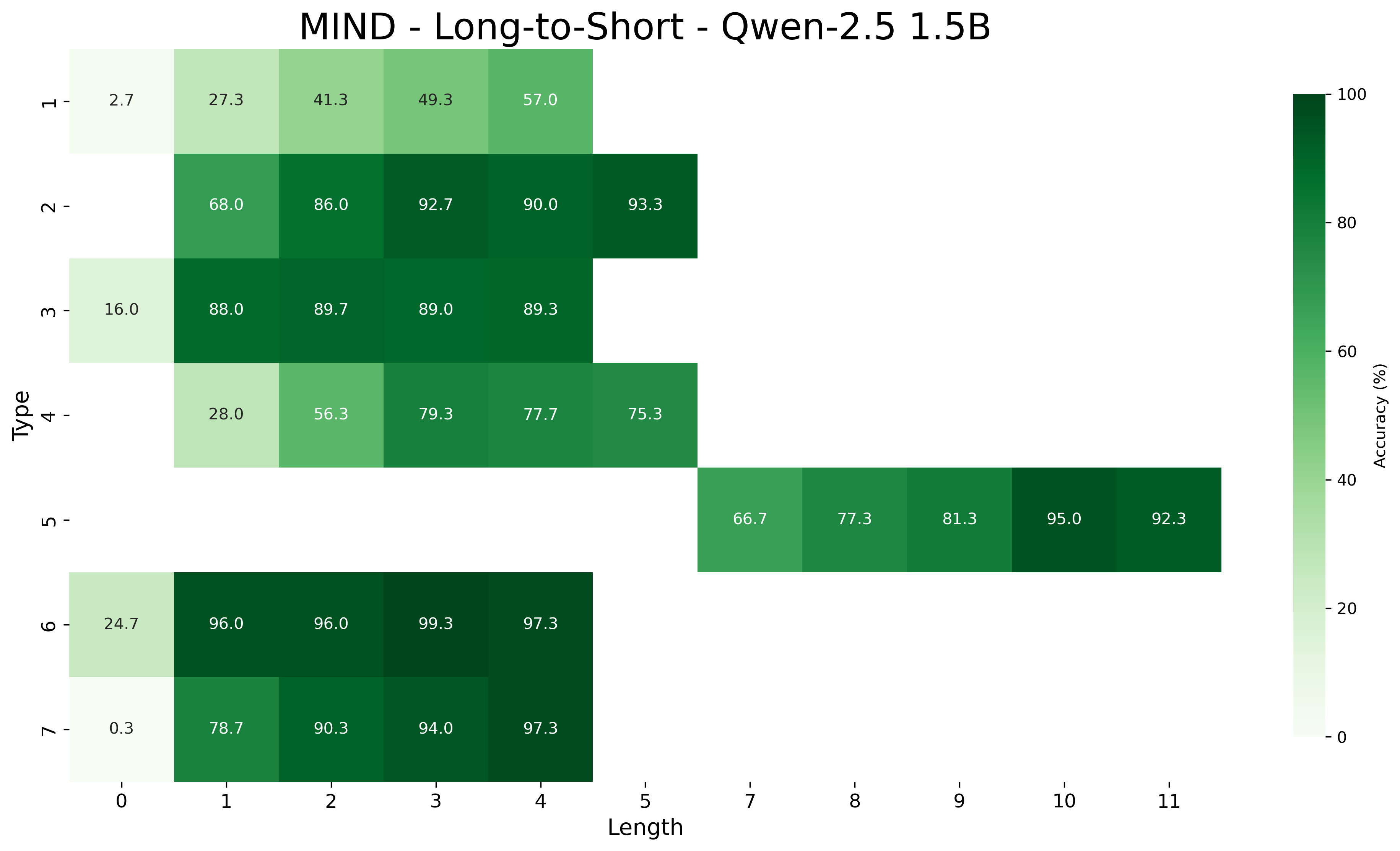
## Heatmap: MIND - Long-to-Short - Qwen-2.5 1.5B
### Overview
The image is a heatmap displaying the accuracy (%) of a model (MIND - Long-to-Short - Qwen-2.5 1.5B) across different 'Type' categories (1-7) and 'Length' categories (0-11). The color intensity represents the accuracy, with darker green indicating higher accuracy and lighter green indicating lower accuracy. Some cells are missing, indicating no data for those combinations.
### Components/Axes
* **Title:** MIND - Long-to-Short - Qwen-2.5 1.5B
* **Y-axis:** 'Type' labeled 1 to 7.
* **X-axis:** 'Length' labeled 0 to 11.
* **Colorbar (Accuracy %):** Ranges from 0% to 100%, with a gradient from light green to dark green.
### Detailed Analysis
The heatmap presents accuracy values for different 'Type' and 'Length' combinations.
* **Type 1:**
* Length 0: 2.7%
* Length 1: 27.3%
* Length 2: 41.3%
* Length 3: 49.3%
* Length 4: 57.0%
* **Type 2:**
* Length 1: 68.0%
* Length 2: 86.0%
* Length 3: 92.7%
* Length 4: 90.0%
* Length 5: 93.3%
* **Type 3:**
* Length 0: 16.0%
* Length 1: 88.0%
* Length 2: 89.7%
* Length 3: 89.0%
* Length 4: 89.3%
* **Type 4:**
* Length 0: 28.0%
* Length 1: 56.3%
* Length 2: 79.3%
* Length 3: 77.7%
* Length 4: 75.3%
* **Type 5:**
* Length 7: 66.7%
* Length 8: 77.3%
* Length 9: 81.3%
* Length 10: 95.0%
* Length 11: 92.3%
* **Type 6:**
* Length 0: 24.7%
* Length 1: 96.0%
* Length 2: 96.0%
* Length 3: 99.3%
* Length 4: 97.3%
* **Type 7:**
* Length 0: 0.3%
* Length 1: 78.7%
* Length 2: 90.3%
* Length 3: 94.0%
* Length 4: 97.3%
### Key Observations
* Accuracy generally increases with 'Length' for most 'Type' categories, up to a certain point.
* Types 6 and 7 show high accuracy for lengths 1-4.
* Type 1 has the lowest accuracy overall.
* Type 5 only has data for lengths 7-11.
### Interpretation
The heatmap visualizes the performance of the MIND model on different input types and lengths. The data suggests that the model performs better on certain types of inputs and longer sequences. The lower accuracy for Type 1 and shorter lengths indicates potential weaknesses in handling those specific scenarios. The missing data points suggest that certain combinations of 'Type' and 'Length' were not tested or are not applicable. The high accuracy for Types 6 and 7 with lengths 1-4 indicates that the model is particularly effective for these specific input characteristics.