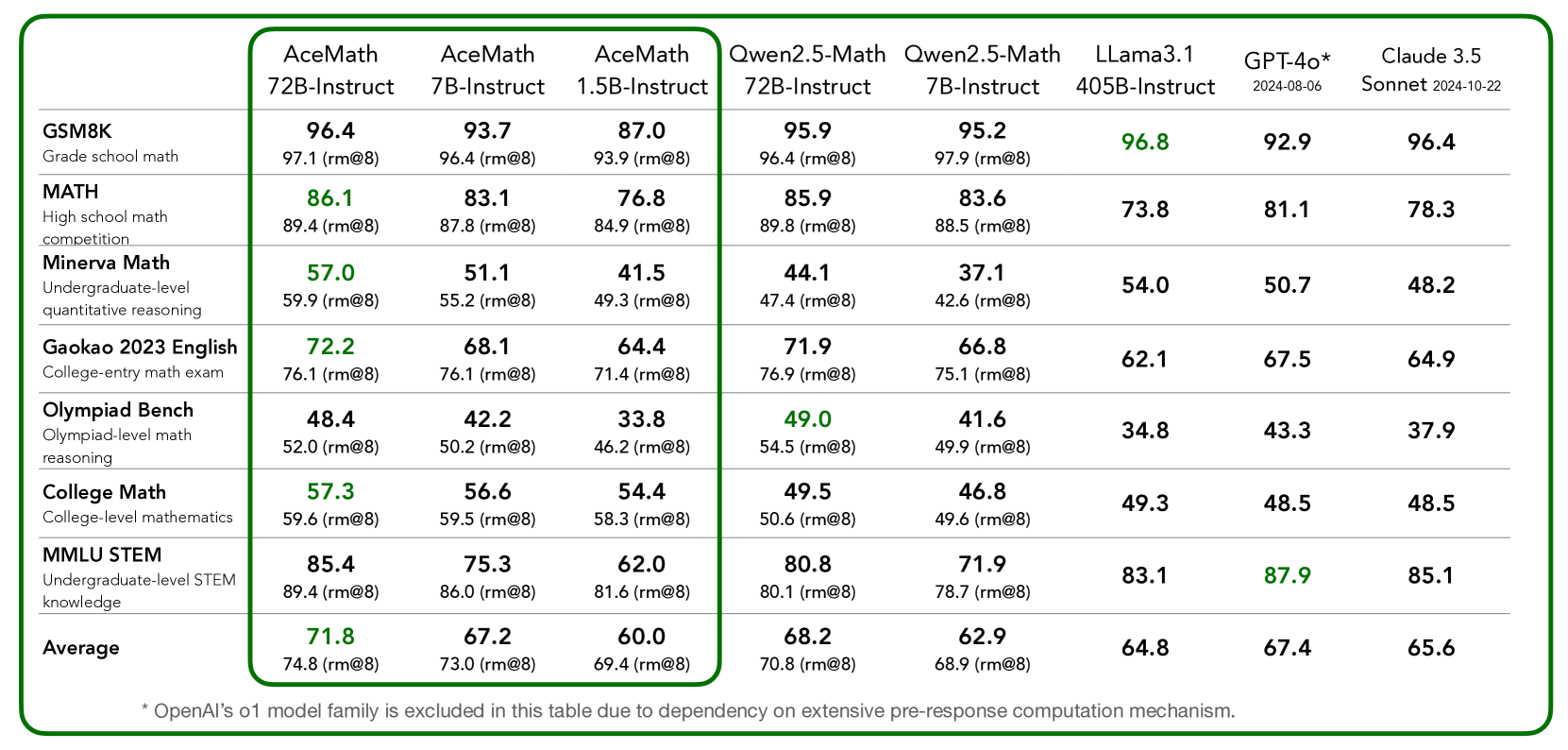
## Data Table: Model Performance on Math and STEM Benchmarks
### Overview
The image presents a data table comparing the performance of several language models on a variety of math and STEM-related benchmarks. The table includes models such as AceMath (various sizes), Qwen2.5-Math (various sizes), Llama3.1, GPT-4o, and Claude 3.5. The benchmarks range from grade school math to undergraduate-level STEM knowledge. The table also includes the average performance across all benchmarks for each model.
### Components/Axes
* **Rows (Benchmarks):**
* GSM8K (Grade school math)
* MATH (High school math competition)
* Minerva Math (Undergraduate-level quantitative reasoning)
* Gaokao 2023 English (College-entry math exam)
* Olympiad Bench (Olympiad-level math reasoning)
* College Math (College-level mathematics)
* MMLU STEM (Undergraduate-level STEM knowledge)
* Average
* **Columns (Models):**
* AceMath 72B-Instruct
* AceMath 7B-Instruct
* AceMath 1.5B-Instruct
* Qwen2.5-Math 72B-Instruct
* Qwen2.5-Math 7B-Instruct
* Llama3.1 405B-Instruct
* GPT-4o (2024-08-06)
* Claude 3.5 Sonnet (2024-10-22)
* **Data:** Each cell contains a numerical score representing the model's performance on the corresponding benchmark. Each score is followed by another score in parenthesis, in the format (rm@8).
### Detailed Analysis or Content Details
Here's a breakdown of the data, organized by benchmark:
* **GSM8K (Grade school math):**
* AceMath 72B-Instruct: 96.4, 97.1 (rm@8)
* AceMath 7B-Instruct: 93.7, 96.4 (rm@8)
* AceMath 1.5B-Instruct: 87.0, 93.9 (rm@8)
* Qwen2.5-Math 72B-Instruct: 95.9, 96.4 (rm@8)
* Qwen2.5-Math 7B-Instruct: 95.2, 97.9 (rm@8)
* Llama3.1 405B-Instruct: 96.8
* GPT-4o: 92.9
* Claude 3.5 Sonnet: 96.4
* **MATH (High school math competition):**
* AceMath 72B-Instruct: 86.1, 89.4 (rm@8)
* AceMath 7B-Instruct: 83.1, 87.8 (rm@8)
* AceMath 1.5B-Instruct: 76.8, 84.9 (rm@8)
* Qwen2.5-Math 72B-Instruct: 85.9, 89.8 (rm@8)
* Qwen2.5-Math 7B-Instruct: 83.6, 88.5 (rm@8)
* Llama3.1 405B-Instruct: 73.8
* GPT-4o: 81.1
* Claude 3.5 Sonnet: 78.3
* **Minerva Math (Undergraduate-level quantitative reasoning):**
* AceMath 72B-Instruct: 57.0, 59.9 (rm@8)
* AceMath 7B-Instruct: 51.1, 55.2 (rm@8)
* AceMath 1.5B-Instruct: 41.5, 49.3 (rm@8)
* Qwen2.5-Math 72B-Instruct: 44.1, 47.4 (rm@8)
* Qwen2.5-Math 7B-Instruct: 37.1, 42.6 (rm@8)
* Llama3.1 405B-Instruct: 54.0
* GPT-4o: 50.7
* Claude 3.5 Sonnet: 48.2
* **Gaokao 2023 English (College-entry math exam):**
* AceMath 72B-Instruct: 72.2, 76.1 (rm@8)
* AceMath 7B-Instruct: 68.1, 76.1 (rm@8)
* AceMath 1.5B-Instruct: 64.4, 71.4 (rm@8)
* Qwen2.5-Math 72B-Instruct: 71.9, 76.9 (rm@8)
* Qwen2.5-Math 7B-Instruct: 66.8, 75.1 (rm@8)
* Llama3.1 405B-Instruct: 62.1
* GPT-4o: 67.5
* Claude 3.5 Sonnet: 64.9
* **Olympiad Bench (Olympiad-level math reasoning):**
* AceMath 72B-Instruct: 48.4, 52.0 (rm@8)
* AceMath 7B-Instruct: 42.2, 50.2 (rm@8)
* AceMath 1.5B-Instruct: 33.8, 46.2 (rm@8)
* Qwen2.5-Math 72B-Instruct: 49.0, 54.5 (rm@8)
* Qwen2.5-Math 7B-Instruct: 41.6, 49.9 (rm@8)
* Llama3.1 405B-Instruct: 34.8
* GPT-4o: 43.3
* Claude 3.5 Sonnet: 37.9
* **College Math (College-level mathematics):**
* AceMath 72B-Instruct: 57.3, 59.6 (rm@8)
* AceMath 7B-Instruct: 56.6, 59.5 (rm@8)
* AceMath 1.5B-Instruct: 54.4, 58.3 (rm@8)
* Qwen2.5-Math 72B-Instruct: 49.5, 50.6 (rm@8)
* Qwen2.5-Math 7B-Instruct: 46.8, 49.6 (rm@8)
* Llama3.1 405B-Instruct: 49.3
* GPT-4o: 48.5
* Claude 3.5 Sonnet: 48.5
* **MMLU STEM (Undergraduate-level STEM knowledge):**
* AceMath 72B-Instruct: 85.4, 89.4 (rm@8)
* AceMath 7B-Instruct: 75.3, 86.0 (rm@8)
* AceMath 1.5B-Instruct: 62.0, 81.6 (rm@8)
* Qwen2.5-Math 72B-Instruct: 80.8, 80.1 (rm@8)
* Qwen2.5-Math 7B-Instruct: 71.9, 78.7 (rm@8)
* Llama3.1 405B-Instruct: 83.1
* GPT-4o: 87.9
* Claude 3.5 Sonnet: 85.1
* **Average:**
* AceMath 72B-Instruct: 71.8, 74.8 (rm@8)
* AceMath 7B-Instruct: 67.2, 73.0 (rm@8)
* AceMath 1.5B-Instruct: 60.0, 69.4 (rm@8)
* Qwen2.5-Math 72B-Instruct: 68.2, 70.8 (rm@8)
* Qwen2.5-Math 7B-Instruct: 62.9, 68.9 (rm@8)
* Llama3.1 405B-Instruct: 64.8
* GPT-4o: 67.4
* Claude 3.5 Sonnet: 65.6
### Key Observations
* AceMath 72B-Instruct generally performs the best among the AceMath models, followed by 7B-Instruct and then 1.5B-Instruct.
* The performance of all models varies significantly across different benchmarks. For example, all models score higher on GSM8K than on Minerva Math.
* GPT-4o and Claude 3.5 show competitive performance across most benchmarks.
* The (rm@8) values are consistently higher than the primary scores, suggesting a potential improvement in performance under specific conditions or evaluation metrics.
### Interpretation
The data suggests that model size and architecture play a significant role in performance on math and STEM benchmarks. Larger models like AceMath 72B-Instruct tend to outperform smaller models like AceMath 1.5B-Instruct. However, the choice of model also depends on the specific task, as some models may be better suited for certain benchmarks than others. The inclusion of (rm@8) values indicates that there are variations in how these models are evaluated, and further investigation into the meaning of "rm@8" would be beneficial. The footnote indicates that OpenAI's o1 model family is excluded due to dependency on extensive pre-response computation mechanism.