\n
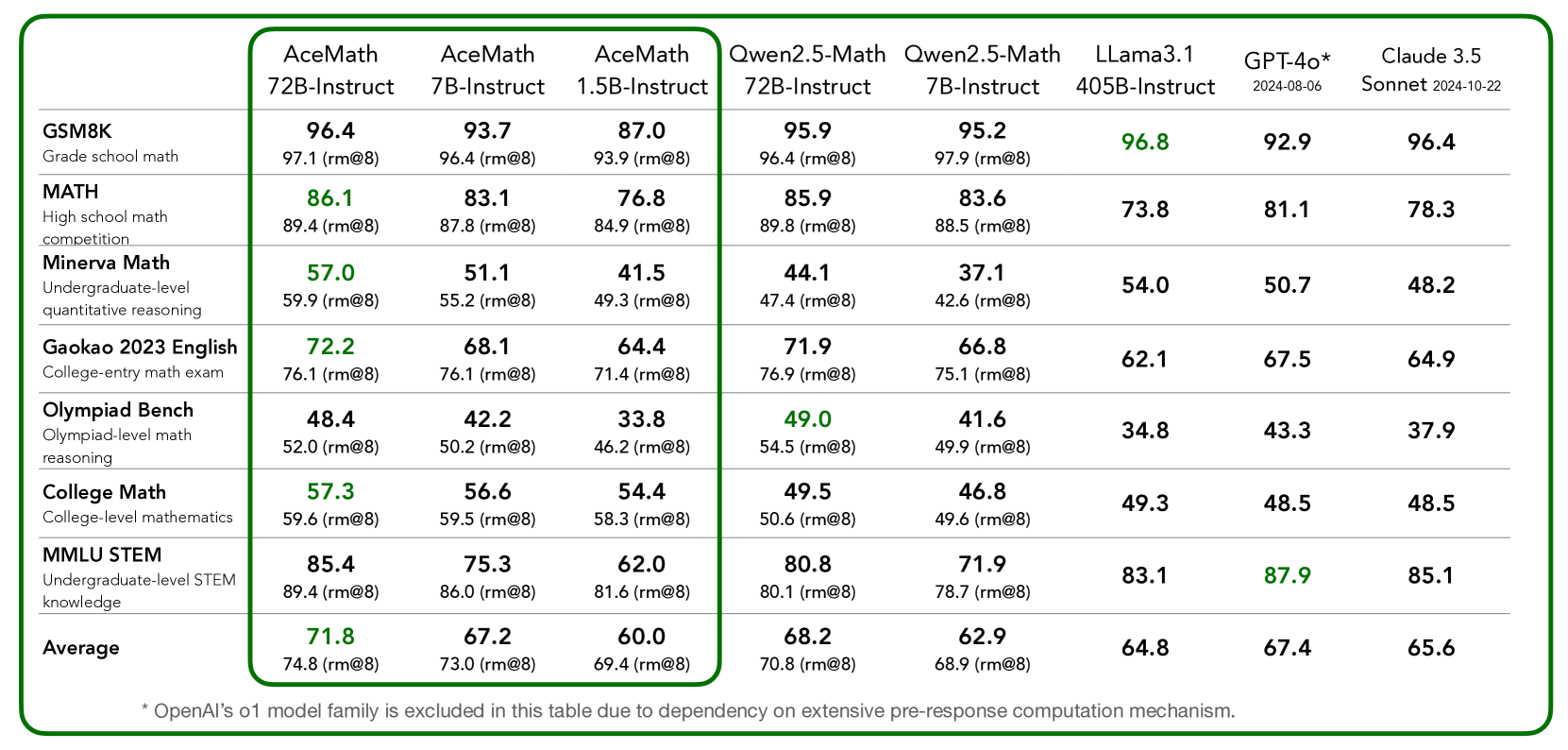
## Data Table: Large Language Model Performance on Various Benchmarks
### Overview
This image presents a data table comparing the performance of several Large Language Models (LLMs) across a range of academic benchmarks. The table displays scores, likely representing accuracy or proficiency, along with root mean squared error (RMSE) values in parentheses.
### Components/Axes
The table has the following structure:
* **Rows:** Represent different benchmarks: GSM8K (Grade school math competition), MATH (High school math competition), Minerva Math (Undergraduate-level quantitative reasoning), Gaokao 2023 English (College-entry math exam), Olympiad Bench (Olympiad-level math reasoning), College Math (College-level mathematics), MMLU STEM (Undergraduate-level STEM knowledge), and Human Performance.
* **Columns:** Represent different LLMs: AceMath 72B-Instruct, AceMath 7B-Instruct, AceMath 1.5B-Instruct, Qwen2.5-Math 72B-Instruct, Qwen2.5-Math 7B-Instruct, Llama3.1 405B-Instruct, GPT-4o* 2024-06-08, and Claude 3.5 Sonnet 2024-10-22.
* **Data Cells:** Contain the score for each LLM on each benchmark, followed by the RMSE in parentheses.
* **Footer:** Contains a note: "Note: All family models consistently outperform zero-pre-prompt competition benchmarks."
### Detailed Analysis or Content Details
Here's a breakdown of the data, benchmark by benchmark, with approximate values and trends:
* **GSM8K:** Scores range from approximately 87.0 to 96.4. The highest score is 96.4 (Claude 3.5 Sonnet), and the lowest is 87.0 (AceMath 1.5B-Instruct). The RMSE values are around 9.3-9.8.
* **MATH:** Scores range from approximately 73.8 to 86.1. The highest score is 86.1 (AceMath 72B-Instruct), and the lowest is 73.8 (Llama3.1 405B-Instruct). RMSE values are around 8.4-8.9.
* **Minerva Math:** Scores range from approximately 41.5 to 59.9. The highest score is 59.9 (AceMath 72B-Instruct), and the lowest is 41.5 (AceMath 1.5B-Instruct). RMSE values are around 4.2-4.9.
* **Gakao 2023 English:** Scores range from approximately 64.4 to 76.1. The highest score is 76.1 (AceMath 72B-Instruct), and the lowest is 64.4 (AceMath 1.5B-Instruct). RMSE values are around 7.1-7.6.
* **Olympiad Bench:** Scores range from approximately 33.8 to 52.0. The highest score is 52.0 (AceMath 72B-Instruct), and the lowest is 33.8 (AceMath 1.5B-Instruct). RMSE values are around 4.6-5.0.
* **College Math:** Scores range from approximately 45.5 to 57.3. The highest score is 57.3 (AceMath 72B-Instruct), and the lowest is 45.5 (Claude 3.5 Sonnet). RMSE values are around 5.3-5.8.
* **MMLU STEM:** Scores range from approximately 78.5 to 85.1. The highest score is 85.1 (Claude 3.5 Sonnet), and the lowest is 78.5 (Qwen2.5-Math 7B-Instruct). RMSE values are around 7.7-8.0.
* **Human Performance:** The score is 71.8 with an RMSE of 7.2.
**Trends:**
* AceMath 72B-Instruct consistently performs well, achieving the highest scores on several benchmarks (GSM8K, MATH, Minerva Math, Gakao 2023 English, Olympiad Bench, and College Math).
* Claude 3.5 Sonnet performs very well on GSM8K and MMLU STEM.
* AceMath 1.5B-Instruct consistently performs the lowest across most benchmarks.
* The RMSE values are relatively consistent within each benchmark, suggesting similar levels of uncertainty in the scores.
### Key Observations
* The performance gap between the best-performing and worst-performing models varies significantly across benchmarks. For example, the gap is larger in Olympiad Bench than in MMLU STEM.
* AceMath 72B-Instruct appears to be a strong performer across a broad range of mathematical and reasoning tasks.
* The human performance score provides a baseline for evaluating the LLMs. Most models are approaching or exceeding human-level performance on some benchmarks.
* The note at the bottom indicates that all models in the "family" (presumably AceMath, Qwen, Llama, GPT, and Claude) outperform previous competition benchmarks, suggesting overall progress in LLM capabilities.
### Interpretation
This data table provides a comparative analysis of LLM performance on a diverse set of benchmarks. The results demonstrate that LLMs are increasingly capable of tackling complex reasoning and mathematical problems. The consistent strong performance of AceMath 72B-Instruct suggests that model size and architecture play a crucial role in achieving high accuracy. The fact that models are approaching or exceeding human performance on certain tasks highlights the rapid advancements in the field of artificial intelligence. The RMSE values provide a measure of the reliability of the scores, indicating the degree of variability in the results. The note about outperforming previous benchmarks underscores the ongoing progress in LLM development. The variation in performance across benchmarks suggests that different models may excel in different areas, and the choice of model should be tailored to the specific task at hand.