TECHNICAL ASSET FINGERPRINT
544009d7ab695356cf2eea99
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
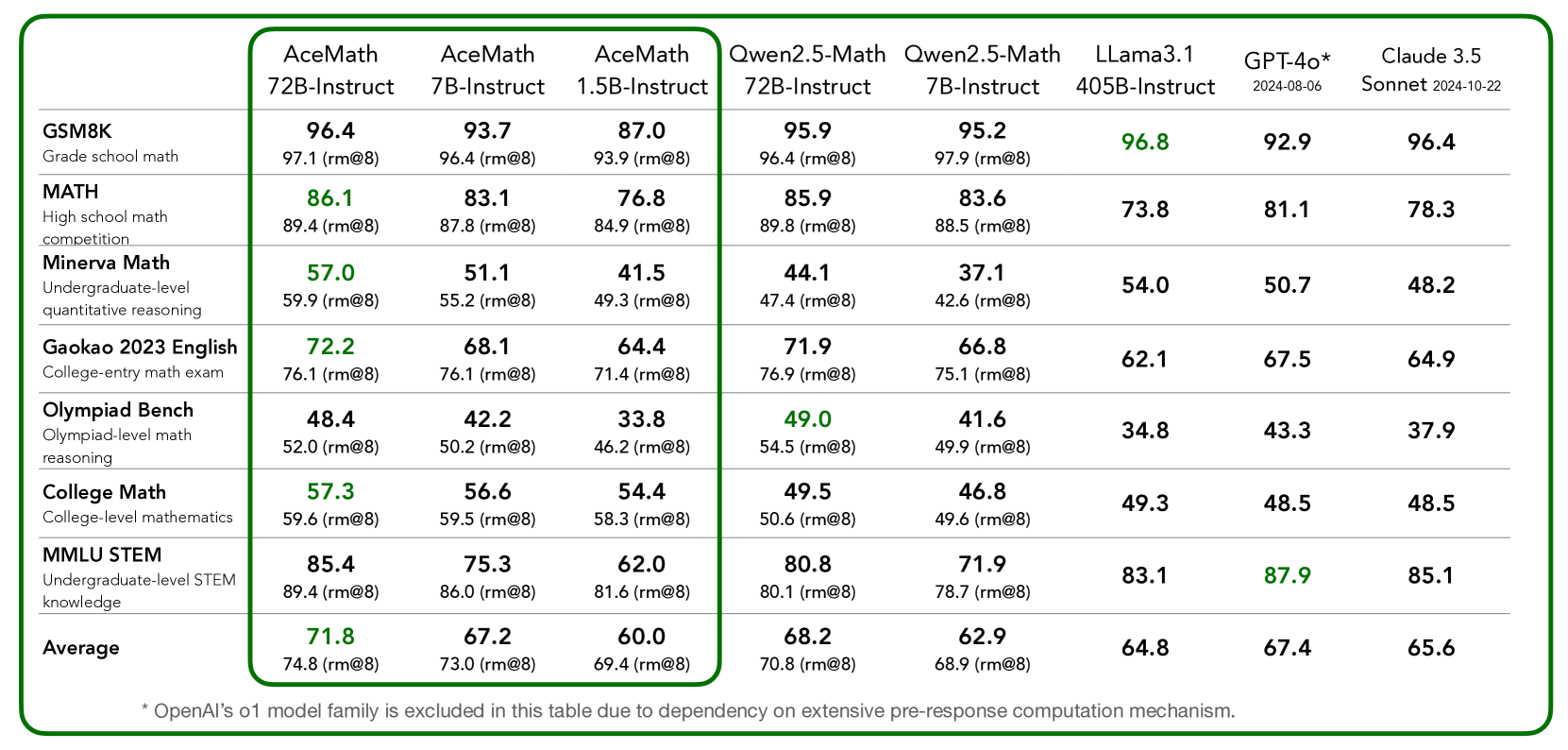
## Table: AI Model Performance Comparison on Mathematical Benchmarks
### Overview
The image displays a detailed performance comparison table of various large language models (LLMs) across a suite of mathematical reasoning benchmarks. The table is enclosed within a green border, with the first three columns (AceMath models) further highlighted by an inner green border. The data presents two performance metrics for each model-benchmark pair: a primary score and a secondary score labeled "(rm@8)". Some primary scores are highlighted in green, indicating the highest performance in that row.
### Components/Axes
**Column Headers (Models):**
1. **AceMath 72B-Instruct**
2. **AceMath 7B-Instruct**
3. **AceMath 1.5B-Instruct**
4. **Qwen2.5-Math 72B-Instruct**
5. **Qwen2.5-Math 7B-Instruct**
6. **LLama3.1 405B-Instruct**
7. **GPT-4o\*** (with footnote: `2024-08-06`)
8. **Claude 3.5 Sonnet** (with footnote: `2024-10-22`)
**Row Headers (Benchmarks):**
1. **GSM8K** (Description: Grade school math)
2. **MATH** (Description: High school math competition)
3. **Minerva Math** (Description: Undergraduate-level quantitative reasoning)
4. **Gaokao 2023 English** (Description: College-entry math exam)
5. **Olympiad Bench** (Description: Olympiad-level math reasoning)
6. **College Math** (Description: College-level mathematics)
7. **MMLU STEM** (Description: Undergraduate-level STEM knowledge)
8. **Average** (No description)
**Footnote:** Located at the bottom of the table: `* OpenAI's o1 model family is excluded in this table due to dependency on extensive pre-response computation mechanism.`
### Detailed Analysis
The table contains the following performance data. The primary score is listed first, with the "(rm@8)" score directly below it in the same cell. Green-highlighted scores are marked with an asterisk (*) for clarity in this text representation.
| Benchmark | AceMath 72B-Instruct | AceMath 7B-Instruct | AceMath 1.5B-Instruct | Qwen2.5-Math 72B-Instruct | Qwen2.5-Math 7B-Instruct | LLama3.1 405B-Instruct | GPT-4o* | Claude 3.5 Sonnet |
| :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- | :--- |
| **GSM8K** | 96.4<br>97.1 (rm@8) | 93.7<br>96.4 (rm@8) | 87.0<br>93.9 (rm@8) | 95.9<br>96.4 (rm@8) | 95.2<br>97.9 (rm@8) | **96.8***<br>— | 92.9<br>— | 96.4<br>— |
| **MATH** | **86.1***<br>89.4 (rm@8) | 83.1<br>87.8 (rm@8) | 76.8<br>84.9 (rm@8) | 85.9<br>89.8 (rm@8) | 83.6<br>88.5 (rm@8) | 73.8<br>— | 81.1<br>— | 78.3<br>— |
| **Minerva Math** | **57.0***<br>59.9 (rm@8) | 51.1<br>55.2 (rm@8) | 41.5<br>49.3 (rm@8) | 44.1<br>47.4 (rm@8) | 37.1<br>42.6 (rm@8) | 54.0<br>— | 50.7<br>— | 48.2<br>— |
| **Gaokao 2023 English** | **72.2***<br>76.1 (rm@8) | 68.1<br>76.1 (rm@8) | 64.4<br>71.4 (rm@8) | 71.9<br>76.9 (rm@8) | 66.8<br>75.1 (rm@8) | 62.1<br>— | 67.5<br>— | 64.9<br>— |
| **Olympiad Bench** | 48.4<br>52.0 (rm@8) | 42.2<br>50.2 (rm@8) | 33.8<br>46.2 (rm@8) | **49.0***<br>54.5 (rm@8) | 41.6<br>49.9 (rm@8) | 34.8<br>— | 43.3<br>— | 37.9<br>— |
| **College Math** | **57.3***<br>59.6 (rm@8) | 56.6<br>59.5 (rm@8) | 54.4<br>58.3 (rm@8) | 49.5<br>50.6 (rm@8) | 46.8<br>49.6 (rm@8) | 49.3<br>— | 48.5<br>— | 48.5<br>— |
| **MMLU STEM** | 85.4<br>89.4 (rm@8) | 75.3<br>86.0 (rm@8) | 62.0<br>81.6 (rm@8) | 80.8<br>80.1 (rm@8) | 71.9<br>78.7 (rm@8) | 83.1<br>— | **87.9***<br>— | 85.1<br>— |
| **Average** | **71.8***<br>74.8 (rm@8) | 67.2<br>73.0 (rm@8) | 60.0<br>69.4 (rm@8) | 68.2<br>70.8 (rm@8) | 62.9<br>68.9 (rm@8) | 64.8<br>— | 67.4<br>— | 65.6<br>— |
**Note on Data:** The "(rm@8)" scores are only provided for the AceMath and Qwen2.5-Math model families. The LLama3.1, GPT-4o, and Claude 3.5 Sonnet columns contain only the primary score, with no secondary metric listed.
### Key Observations
1. **Top Performer per Benchmark:** The green highlights show that the **AceMath 72B-Instruct** model achieves the highest primary score on 5 out of 7 individual benchmarks (MATH, Minerva Math, Gaokao 2023 English, College Math) and the overall Average. **LLama3.1 405B-Instruct** leads on GSM8K, **Qwen2.5-Math 72B-Instruct** leads on Olympiad Bench, and **GPT-4o*** leads on MMLU STEM.
2. **Model Family Trends:** Within the AceMath and Qwen2.5-Math families, performance generally scales with model size (72B > 7B > 1.5B/7B), though the gap is sometimes small.
3. **Benchmark Difficulty:** Scores are highest on GSM8K (grade school math), with most models above 90. Scores are lowest on Olympiad Bench (olympiad-level), with most models below 50. This indicates a clear hierarchy of difficulty.
4. **Metric Comparison:** For the models where both metrics are provided, the "(rm@8)" score is consistently higher than the primary score, suggesting it may represent a best-of-k or refined evaluation metric.
5. **Competitive Landscape:** The AceMath 72B model is highly competitive with, and often outperforms, much larger models like LLama3.1 405B and proprietary models like GPT-4o and Claude 3.5 Sonnet on these specific mathematical tasks.
### Interpretation
This table serves as a benchmark report card, demonstrating the mathematical reasoning capabilities of the AceMath model series relative to other state-of-the-art LLMs. The data suggests that the AceMath 72B-Instruct model is a specialized and highly effective model for mathematical tasks, achieving top-tier results across a diverse range of difficulty levels, from grade school to college and competition math.
The consistent outperformance of the AceMath 72B model over the Qwen2.5-Math 72B model on most benchmarks (except Olympiad Bench and MMLU STEM) indicates potential architectural or training data advantages for mathematical reasoning in the AceMath series. The strong performance of the much smaller AceMath 1.5B model, particularly its "(rm@8)" scores which are often close to the 7B models, suggests efficient learning or the effectiveness of the "(rm@8)" evaluation method for smaller models.
The exclusion of OpenAI's o1 model family, as noted in the footnote, is a critical piece of context. It implies that the comparison is focused on models that generate responses without an extensive, explicit multi-step reasoning phase before the final answer, making the benchmark more about the model's inherent, single-pass reasoning capability. The table ultimately positions the AceMath models, especially the 72B variant, as leading open or specialized alternatives to general-purpose frontier models for mathematical applications.
DECODING INTELLIGENCE...