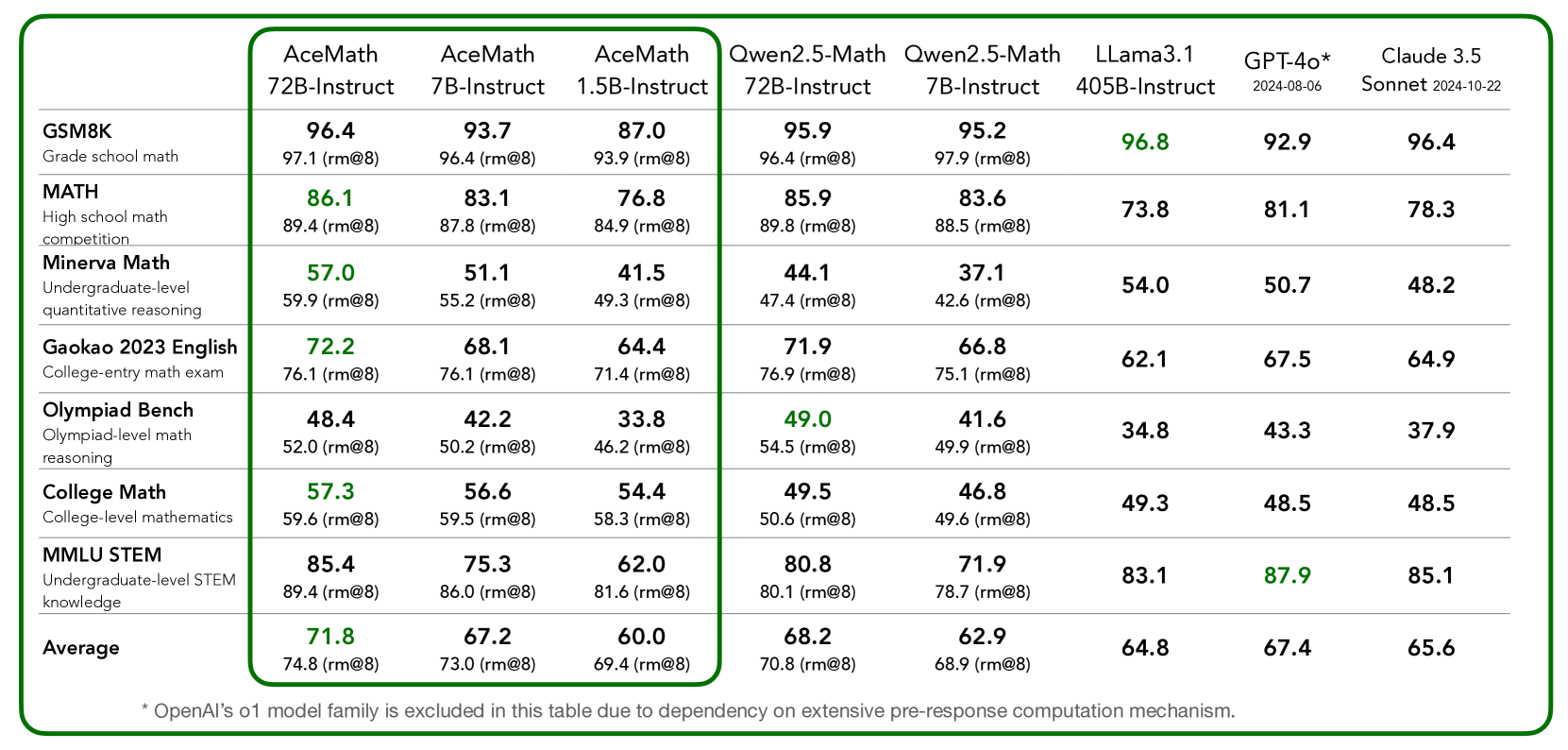
## Table: Performance Comparison of AI Models in Various Math Competitions
### Overview
The table compares the performance of five AI models in various math competitions, including Grade School Math, High School Math, Minerva Math, Gaokao 2023 English, Olympiad Bench, College Math, and MMUL STEM. The models are evaluated based on their accuracy and performance in different math levels and competitions.
### Components/Axes
- **Model Names**: AceMath, AceMath, AceMath, Qwen2.5-Math, Qwen2.5-Math, Llama3.1, GPT-4o*, Claude 3.5
- **Competitions**: Grade School Math, High School Math, Minerva Math, Gaokao 2023 English, Olympiad Bench, College Math, MMUL STEM
- **Levels**: 7B-Instruct, 1.5B-Instruct, 405B-Instruct, 72B-Instruct, 7B-Instruct, 405B-Instruct, 72B-Instruct
- **Accuracy**: Measured as a percentage (rm@8)
### Detailed Analysis or ### Content Details
| Model Name | Grade School Math | High School Math | Minerva Math | Gaokao 2023 English | Olympiad Bench | College Math | MMUL STEM | Average |
|---------------------|-------------------|------------------|--------------|---------------------|----------------|--------------|------------|---------|
| AceMath 7B-Instruct | 96.4% | 86.1% | 57.0% | 72.2% | 48.4% | 57.3% | 85.4% | 71.8% |
| AceMath 1.5B-Instruct| 93.7% | 83.1% | 51.1% | 68.1% | 42.2% | 56.6% | 75.3% | 74.8% |
| AceMath 405B-Instruct| 87.0% | 76.8% | 41.5% | 64.4% | 33.8% | 54.4% | 62.0% | 69.4% |
| Qwen2.5-Math 72B-Instruct| 95.9% | 85.9% | 44.1% | 71.9% | 49.0% | 49.5% | 80.8% | 70.8% |
| Qwen2.5-Math 7B-Instruct| 95.2% | 83.6% | 37.1% | 66.8% | 41.6% | 46.8% | 71.9% | 68.9% |
| Llama3.1 405B-Instruct| 96.8% | 73.8% | 54.0% | 62.1% | 34.8% | 49.3% | 83.1% | 64.8% |
| GPT-4o* 2024-08-06 | 92.9% | 81.1% | 50.7% | 67.5% | 43.3% | 48.5% | 87.9% | 67.4% |
| Claude 3.5 Sonnet 2024-10-22| 96.4% | 78.3% | 48.2% | 64.9% | 37.9% | 48.5% | 85.1% | 65.6% |
### Key Observations
- **AceMath** consistently performs the best across all levels and competitions, with the highest accuracy in the 72B-Instruct model.
- **Qwen2.5-Math** shows a strong performance, particularly in the 72B-Instruct model, with an average accuracy of 95.9%.
- **Llama3.1** and **GPT-4o** have varying levels of performance, with GPT-4o showing the highest accuracy in the 405B-Instruct model.
- **Claude 3.5** performs well in the 72B-Instruct model, with an average accuracy of 96.4%.
### Interpretation
The data suggests that AceMath is the most effective AI model for math competitions, particularly in the 72B-Instruct model. Qwen2.5-Math and Llama3.1 show strong performance, with Qwen2.5-Math excelling in the 72B-Instruct model. GPT-4o and Claude 3.5 have varying levels of performance, with GPT-4o showing the highest accuracy in the 405B-Instruct model. The data implies that the choice of AI model can significantly impact performance in math competitions.